Hi, I’m using Keras API for tabular data with embedding, conv1D and sequential with onehot encoding to get a merged model more efficient (after a concatenation layer). I’m very interesting in adding a Keras gradient boosting model but I guess it won’t be possible to get the output layer (and input) to concatenate multiple outputs and create a merged model ? It seems we can only fit the gradient model (without compile step) as any other gradient boosting models (Xgb, Lgb, Cat…). Do I miss something ? Thank you very much for your information
I read the intermediate colab page, but my question was about the gradient boosting model which is much more efficient than a random forest for tabular data.
In the page, It seems that only random forest can be concatenated with functional API . In addition, my understanding (but I need to go deeper in the example provided in the page) is that the training is performed in 2 steps (not in //). My objective is to use multiple heads made of functional API (head for embedding layer, head for Conv1D…) to compute a tabular dataset in // and concatenate the // heads into a final stream (still API) for a prediction ( with some dense layers and finally a softmax activation for example). Of course, a head with gradient boosting would improve the result of the concatenation.
I did it with a head made of Decision Forest model (from Keras deep_neural_decision_forests) but it was not very powerfull .
By the way, it seems (not important) that you should change vocabulary_size in the data pipeline by vocab_size because it leads to an error in google colab notebook.
Bonjour/Hello Laurent :),
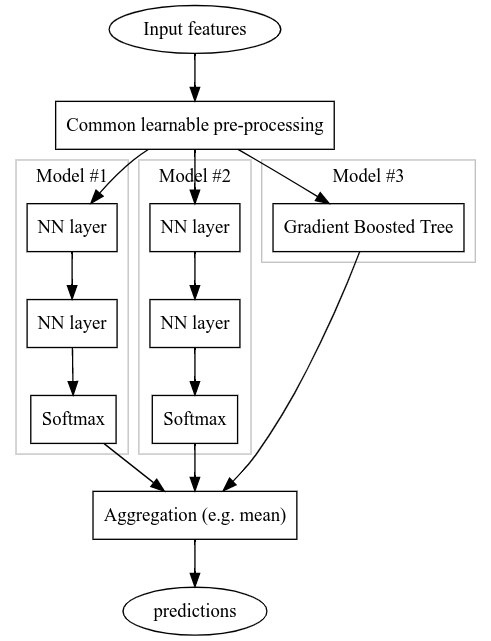
To make it more visual, here is the model you describe as I understand it:
(Assuming this is the model you describe), this configuration is possible, but there are some caveats:
The TF-DF models don’t backpropagate gradients (yet). It means that the parameters of the “Common learnable pre-processing” part cannot be trained through the GBT. Instead, the pre-processing needs be trained with the gradients back-propagated through the “model #1” and “model #2”.
This implies a 2 steps training:
- Training of “Common learnable pre-processing” + “model #1” + “model #2”.
- Training of “GBT model”.
If there are no “Common learnable pre-processing” stages, all the models (including the GBT) can be trained in parallel (i.e. in the same session call). However, this might not be optimal as GBT trains in exactly on epoch, while NNs generally train over multiple ones. Instead, it will be more interesting to train the GBT and the NN independently (but possibly at the same time).
This colab demonstrates how to train the ensemble shown in the figure. I hope this helps. The API is a bit verbosy, but hopefully, this will improve :).
Cheers,
1 Like
Hello @laurent_pourchot,
It is possible both to stack TF-DF “on top of existing” model (see intermediate colab) as well as to stack a model/set-of-operations (e.g. concatenate output) on top of a TF-DF (currently not demonstrated in a colab) using the Sequential or Functional Keras API. What’s important is that “fit” is called the TF-DF model.
2 Likes
Hello Mathieu,
You have understood my request and your picture is perfect. I also understand your very clear answer, thank you very much.
This kind of // configuration works with a decision Forest posted on Keras so I was dreaming of a better model such as gradient boosting.
Yesterday, I tested your model from the tuto but with 50 features and 100 000 rows (50 inputs layers in a loop) concatenated +3 Dense layers + softmax with multiclass and then a layer ( not the final softmax) into the gradient model argument. It works  but overfit quickly
but overfit quickly  ( even with the early stopping in the gradient model and a callback in the functiional API).
( even with the early stopping in the gradient model and a callback in the functiional API).
Thank you again for your explanations and I hope for a future gradient model to make NN + trees more efficient on tabular structured data. ( atention layers and tabnet gives also poor result in comparison to gradient).
1 Like