I am interested in supervised document classification. I use a simple workflow to take english journal articles from arxiv, extract/clean the text into sentences (nltk.tokenize.sent_tokenize()), encode them with very standard BERT (small and large), and then visualize clustering behavior with UMAP.
I obtained a corpus of Russian journal articles on two different distinct topics and used the same pipeline using RuBERT (inputs were in Russian). I expected to see clustering and this is what I got: 
And I was pleased with that. I cannot read Russian so I only did minimal data cleaning, and this appears to be “good” clustering.
My next thought was that if I pass the same data through the standard English BERT models, I would expect almost random behavior. I would not expect the vocabulary encodings to line up properly (“scientist” and “ученый” would not have same assignment). Yet this is the UMAP embedding of the same Russian sentences via the English BERT model:
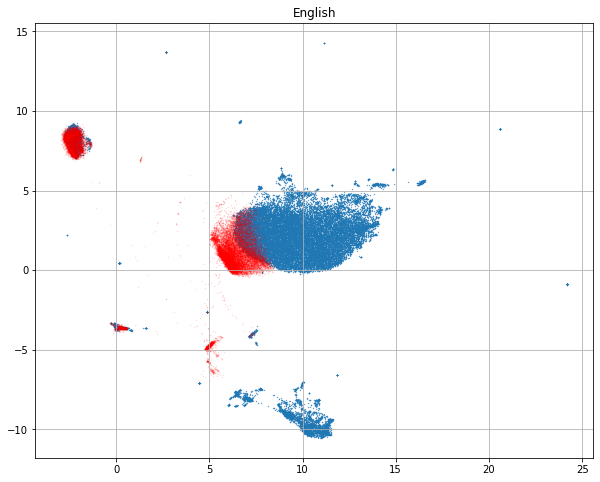
I expected nearly complete overlap between the two Russian document classes when encoded with English BERT.
I’d like to understand this behavior better because I want to do more work with non-English data sets.