I have a sequence-to-sequence model (with LSTM encoder and decoder and RMSprop optimiser) that was originally built for Keras 2.2 with the CNTK backend. We need to modernise this model as CNTK has been end of life for some time. Tensorflow is now the only backend available for Keras.
Under the Keras 2.2 with CNTK 2.7 backend the final accuracy on unseen data is about 97%. After a few minor changes to get it to work on a modern Tensorflow 2.12 and the same hyperparameters, the final accuracy is about 11%, with training loss rising sharply after a number of epochs.
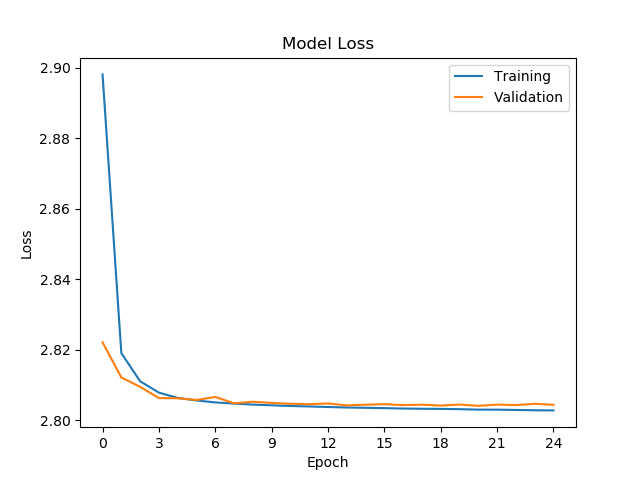
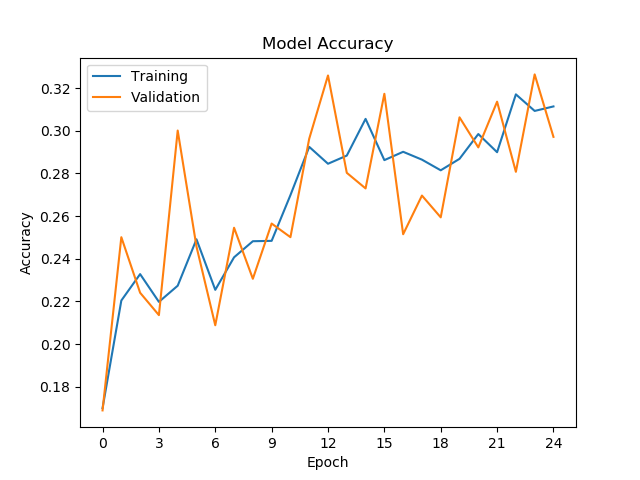
Training graphs with Keras 2.2 and CNTK 2.7 CPU:
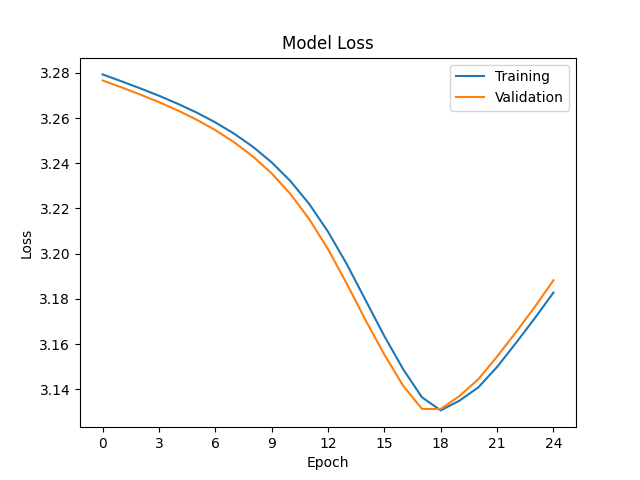
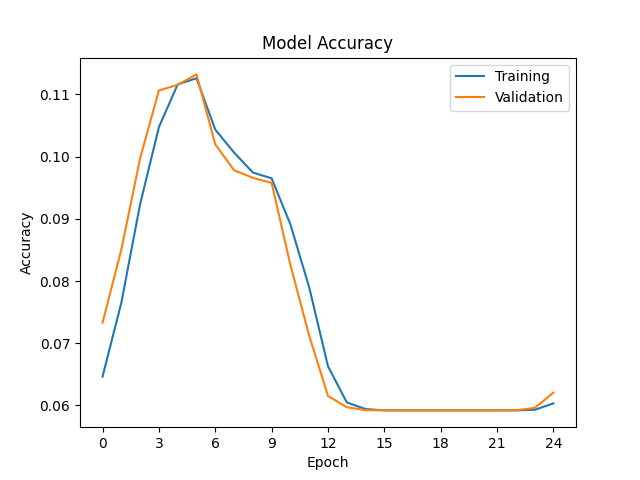
Training graphs with Tensorflow/Keras 2.12 GPU (CPU similar):
Under Keras 2.2/CNTK 2.7, the RMSprop optimiser was initialised using keras.optimizers.deserialize(). I have changed the code to create the optimiser directly using keras.optimizers.RMSprop(). This improved the model’s accuracy to 38%, but this is still not up to the accuracy levels of CNTK.
Training graphs with Tensorflow/Keras 2.12 GPU with keras.optimizers.RMSprop:
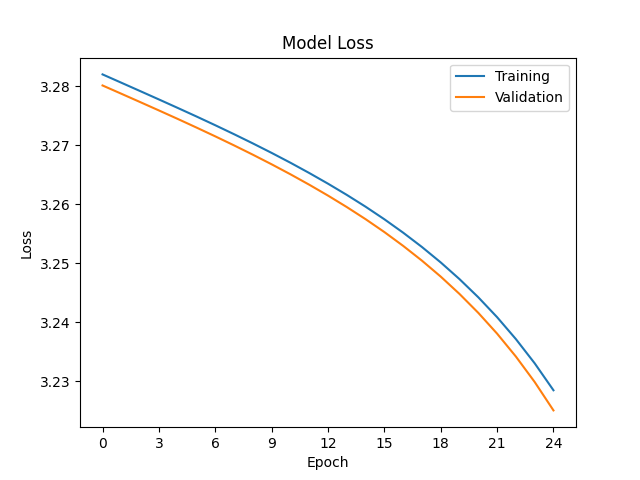

The graphs suggest that the modernised Tensorflow has its learning rate set too high, but the hyperparameters are the same in both cases (learning rate 10^-6). I have already updated lr to learning_rate as per the release notes for Keras 2.3.0.
What has changed between Keras 2.2 and 2.12, or between CNTK and Tensorflow, that I need to update so that the model returns to its previous performance? What further changes do I need to make, and what other caveats do I need to address?