Hi, excited to be here
I’m very new to tensorflow, and was hoping that someone could point me in the right direction.
I want to create a little system that can have inputs in the form of:
Text (inputs can be PDF, Office document, or Picture with text)
Audio (spoken, possibly multiple participants in the same conversation, but also individuals)
Video (same as audio, but with images too)
I want to then be able to find similarities/themes/contexts between them.
Could anyone point me to some existing libraries/models that I can integrate to achieve this? And any useful tutorials?
I was actually wondering whether the videos should include written text in the training, let’s call it phase 1, so that words, sounds, text, and images can provide a basis for a potential phase 2, where also documents and audio recordings are added to the training … That would probably require more training material, but should provide a coherent and inclusive basis for generic applications, which can be further trained and specialised … I’m … just toying with ideas … while I’m learning. Thanks again
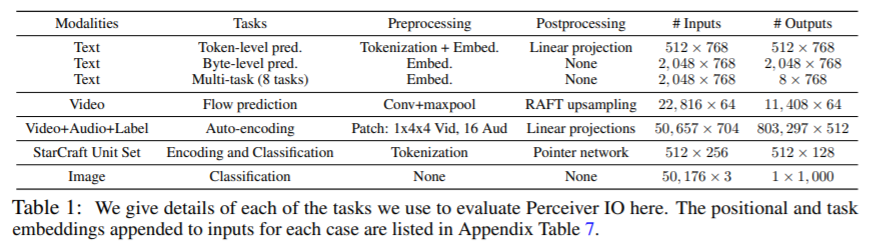
The Perceiver uses attention (building on Transformers [88]) to map inputs of a wide range of modalities to a fixed-size latent space, that is further processed by a deep, fully attentional network. This process decouples the bulk of the network’s processing from the size and modality-specific details of the input, allowing it to scale to large and multimodal data.
We demonstrate the generality of the proposed model by tackling several challenging tasks, showing that Perceiver IO can be used to replace the Transformers used in both BERT [21] and AlphaStar [89]. At the same time, Perceiver IO produces state-of-the-art results on the Sintel optical flow benchmark [10], compelling results on multimodal (video, audio, label) auto-encoding in Kinetics [71], and results comparable to state-of-the-art models on ImageNet image classification [19]. In some cases, Perceiver IO allows us to simplify pipelines and remove domain-specific assumptions. For example, we process language without using tokenizers and fine-tune on multiple classification tasks simultaneously and without requiring [CLS] tokens (see Sec. 4.1), estimate optical flow without relying on explicit architectural features for multiscale correspondence (see Sec. 4.2), and perform image classification with no information about the 2D structure of images (see Sec. 4.5). Perceiver IO can be used as a standalone architecture, in conjunction with {pre, post}-processing steps, and as a part of sophisticated pipelines, in each case matching or beating strong baselines.
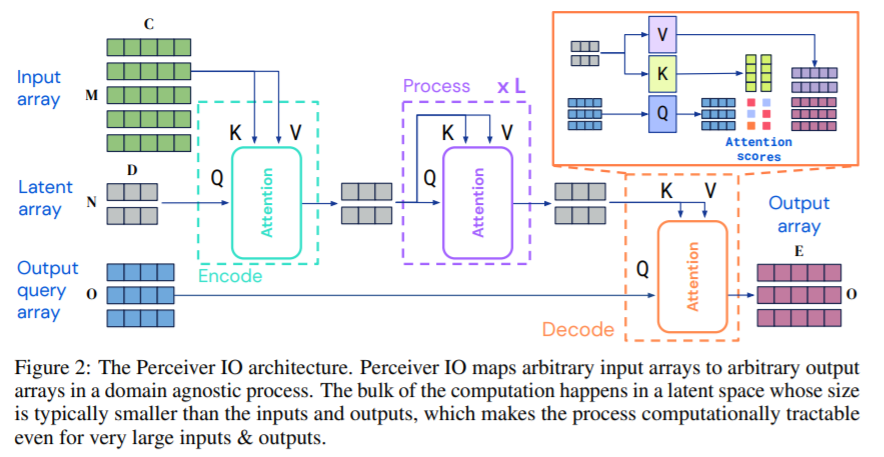
We explore using Perceiver IO for audio-video-label multimodal autoencoding on the Kinetics-700- 2020 dataset [71]. The goal of multimodal autoencoding is to learn a model that can accurately reconstruct multimodal inputs in the the presence of a bottleneck induced by an architecture. This problem has been previously studied using techniques such as Restricted Boltzmann Machines [58], but on much more stereotyped and smaller scale data. Kinetics-700-2020 has video, audio and class labels…
I don’t know at which point you are in your ML journey but you are trying to tackle a hard problem.
What I would do as a start is work only with text and try to extract from it some tags. This can be done with Named Entity Recognition (NER). You’ll get some entities per paragraph and then you can try to work from there
Of course audio and video would also need to be transcribed to text and then you apply the same idea.

 My colleague
My colleague