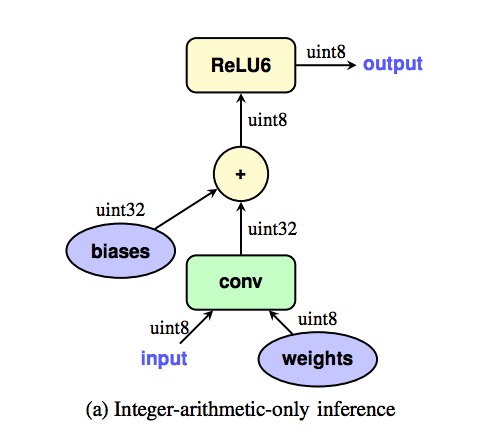
TensorFlow documentation says that during the inference step the weights and triggers are int8 and the bias is int32. The result of the convolution is added to the bias and then the result of the sum is converted from int32 bits to int8. This conversion is not clear to me. I think I would have some options for that. For example, we can use only the most significant or least significant bits to generate the output value in int8, or we can reduce the value and then convert to int8. So how is this conversion done?
I am developing an FPGA accelerator for CNN as a graduation work. I used Quantization Aware Training to get the 8-bit weights. I have extracted the quantized weights from the TFLite interpreter and am validating the weights in C before implementing in VHDL. However, the results aren’t correct and I think I’m missing something when converting the output of Conv Layer from int32 to int8.
Preformatted textchar o = (char)(conv_o + l.bias[m]); // add bias
Preformatted texto = (o < 0) ? 0 : o; // RELU
I hope you can help-me.
Thank you!
Best regards.