Hi TensorFlow team,
I have created a linear regression model that takes a pandas dataframe with five columns and generates an output of array of float arrays of 3 elements. To illustrate this, I have created a Colab notebook linear_regression.ipynb under Colab Notebooks - Google Drive
I have converted the model to Tensorflow Lite (see linear_regression.tflite in the same folder that has the notebook). I am now trying to figure out how to use this model in Java to run on Android. Below is my initial code:
LinearRegression model = LinearRegression.newInstance(context);
double features[] = {0.195312, 0.05913, 0.089844, 0.550781, 0.320312};
ByteBuffer bb = ByteBuffer.allocate(features.length * 4);
for (double f : features)
bb.putFloat((float) f);
// The default code suggested in Android Studio mentions it should be new int[]{1, 1}, so I am not sure
TensorBuffer tb = TensorBuffer.createFixedSize(new int[]{1, 5}, DataType.FLOAT32);
tb.loadBuffer(bb);
LinearRegression.Outputs outputs = model.process(tb);
Sure enough, I got the following exception:
java.lang.IllegalArgumentException: Cannot copy to a TensorFlowLite tensor (serving_default_normalization_input:0) with 4 bytes from a Java Buffer with 20 bytes.
What is the correct way of passing the input to the model and getting output from the model?
1 Like
Hi George_Zheng,
Have you tried without multiplying with * 4? Does it work?
Also I do not think it is necessary to pass ByteBuffer inside the model. You can use directly the float array. You will have lower speed …about 1ms 
Hi @George_Soloupis,
Thanks for your response. I tried without *4 and got java.nio.BufferOverflowException when putting the second float value from the array into the ByteBuffer. FYI, when I click linear_regression.tflite under ml in my Android Studio project, below is the sample code it provides:
try {
LinearRegression model = LinearRegression.newInstance(context);
// Creates inputs for reference.
TensorBuffer inputFeature0 = TensorBuffer.createFixedSize(new int[]{1, 1}, DataType.FLOAT32);
inputFeature0.loadBuffer(byteBuffer);
// Runs model inference and gets result.
LinearRegression.Outputs outputs = model.process(inputFeature0);
TensorBuffer outputFeature0 = outputs.getOutputFeature0AsTensorBuffer();
// Releases model resources if no longer used.
model.close();
} catch (IOException e) {
// TODO Handle the exception
}
Questions:
- Per your suggestion, if I bypass the ByteBuffer, would I still need to load the array values into the TensorBuffer as input to the model?
- How do I “use directly the float array”? Would you please provide sample code for this?
Hi,
Please upload your project to github and let me try it to make some suggestions.
Include the tflite file.
Thanks
H @George_Soloupis,
If you don’t mind, I have created a tarball with a subset of the project (sorry I had to cleanup some sensitive information) and put it under the same Colab folder. You can find test_app.tgz under Colab Notebooks - Google Drive. Once you untar it, you should be able to load it into the Android Studio. Once run, you will have to pick a file (any file is fine since I removed the relevant logic) from the device using the BROWSE button and then click RUN INFERENCE button to trigger the runInference function in MainActivity.java. Let me know if you are trouble access the tarball. I think I made it public but I may need your email to add you to the access list.
Thank you very much for looking into this.
George
Hi,
I have succesfully loaded your project. At the beggining it was givving me the error you have mentioned at the original post.
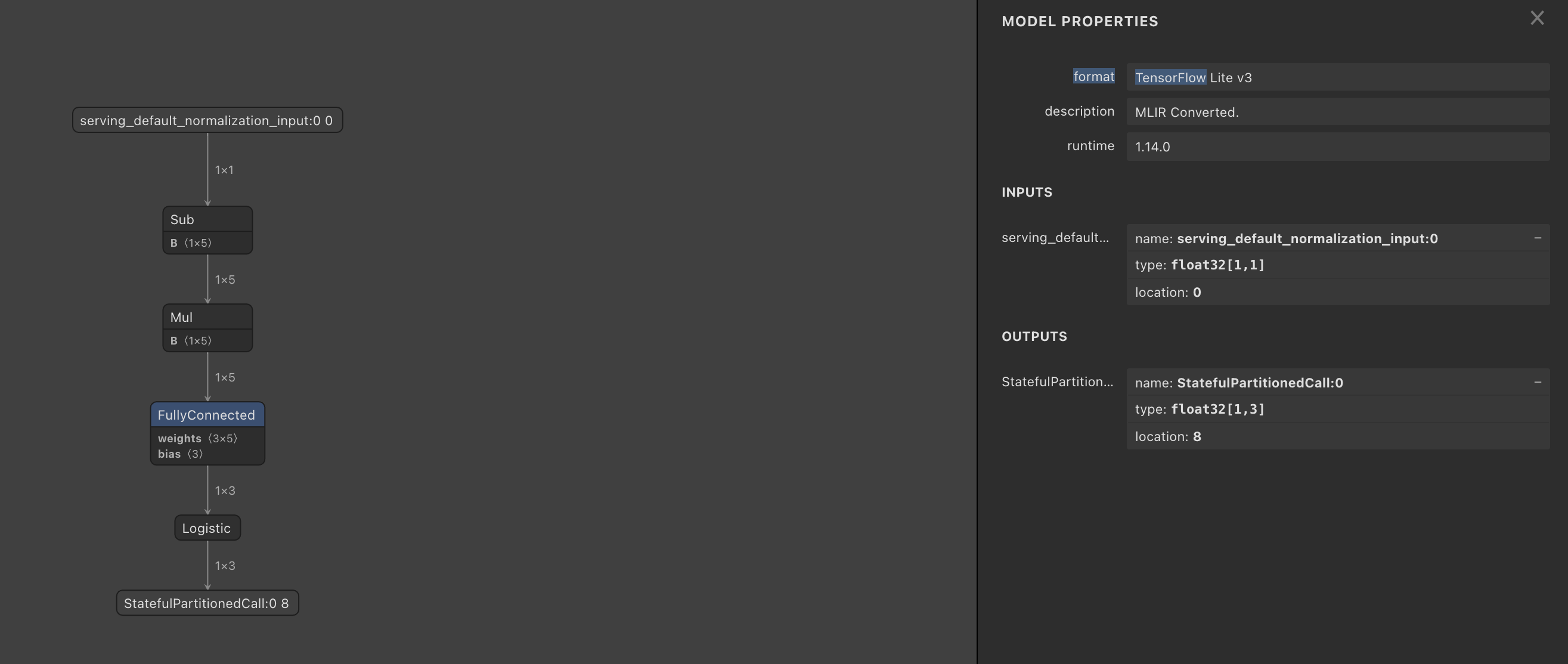
So I uploaded the .tflite file into netron.app and saw:
You see that the model is expecting one item in the float array.
So I changed your code to:
private void runInference() {
long t0 = System.currentTimeMillis();
String path = this.fragment.getPath();
if (path.length()==0) {
displayMessage("No file has been selected yet");
}
try {
TensorBuffer tb = TensorBuffer.createFixedSize(new int[]{1, 1}, DataType.FLOAT32);
double features[] = {0.195312};
ByteBuffer bb = ByteBuffer.allocate(features.length * 4);
for (double f : features)
bb.putFloat((float) f);
tb.loadBuffer(bb);
LinearRegression model = LinearRegression.newInstance(this);
LinearRegression.Outputs outputs = model.process(tb);
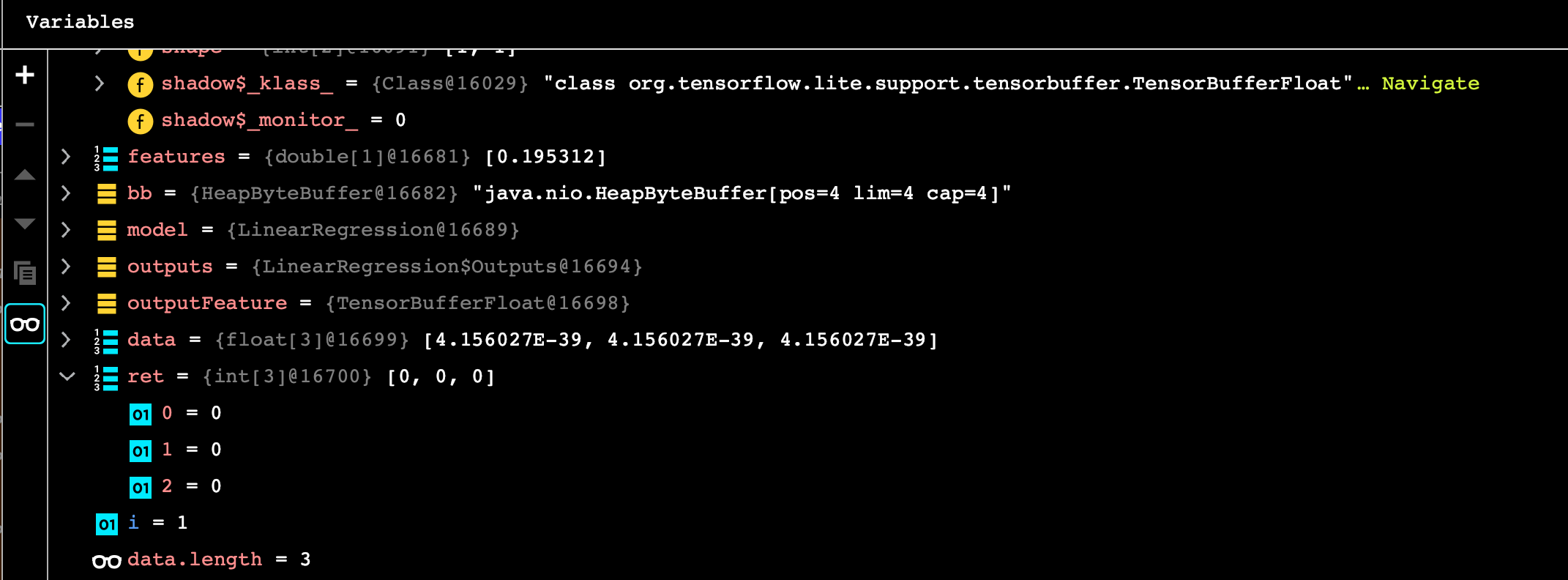
TensorBuffer outputFeature = outputs.getOutputFeature0AsTensorBuffer();
float[] data = outputFeature.getFloatArray();
int[] ret = new int[data.length];
for (int i = 0 ; i < data.length; i++)
{
ret[i] = (int) data[i];
}
displayMessage("finished");
} catch (Throwable t) {
// TODO Handle the exception
Log.d("ERROR", t.getMessage());
}
}
and it finishes correctly without errors.
I do not know if there is a mistake when you have converted your model to .tflite file. Take a look at your colab and if you have issues ping me back.
Happy coding!
Hi @George_Soloupis,
Thanks for looking into this. FYI, the regression model is used as a post-processing step to fine tune some predicted values from an upstream model (not shown in the project I provided you with). I have updated the Colab notebook linear_regression.ipynb under Colab Notebooks - Google Drive to include the step I used to convert .h5 into .tflite. As you can see, the model loaded from the h5 file in the notebook is able to process 5 input values and generate 3 output values. Note that I did have to call adapt() from the Normalization layer on the data with the correct number of elements before instantiating the regression model and loading the weights from the h5 file. I uploaded both .h5 and .tflite models into the netron app and saw the following:
The left is the .h5 model and the right is the .tflite model as you saw earlier. So it seems that the model conversion step that I included in the notebook forced the input size to be 1x1.
Question/request:
- What changes do I need to make in the conversion to change that to 1x5?
- If we can achieve the above, my next step is to verify that I can use this model to generate the same output
[ 30.668777, 111.0412 , 69.47372 ] (after multiplying each by 256) for the given input [0.195312, 0.05913, 0.089844, 0.550781, 0.320312], with only some small variations, if any. I would really appreciate it if you can try this as a quick test.
Thanks,
George
Interesting!
This is what I see from the .h5 model:
and this is after conversion:
Let me ping
@khanhlvg to see if he can sed some light here.
Code:
data = np.array([[0.195312, 0.05913, 0.089844, 0.550781, 0.320312]])
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(data)
lr_model = tf.keras.Sequential([
normalizer,
tf.keras.layers.Dense(units=3, activation='sigmoid')
])
lr_model.load_weights("linear_regression.h5")
target_y = lr_model.predict(data)
print(target_y)
# Convert the model.
converter = tf.lite.TFLiteConverter.from_keras_model(lr_model)
tflite_model = converter.convert()
# Save the model.
with open('model.tflite', 'wb') as f:
f.write(tflite_model)
TensorFlow version 2.7.0
Best
1 Like
I think this is the source of the problem.
IIRC, TFLite needs fixed sized tensors. During conversion TFLite goes through and replaces unknown dimensions with 1. That’s fine for batch-size, but makes a mess for everything else.
Where you’re defining your model, try: input = tf.keras.Input(shape=[5]), or input_shape=[5].
Also the raw-byte-buffer copying is harder than it needs to be. Try using the signature runners instead:
Hi @markdaoust, thanks for the follow-up. I was able to follow your advice to add the input spec:
linear_model = tf.keras.Sequential([
tf.keras.Input(shape=[5]),
tf.keras.layers.Normalization(axis=-1),
layers.Dense(units=3, activation='sigmoid')
])
After converting h5 to tflite and loading the model to netron.app, now I see 1x5 for the input.
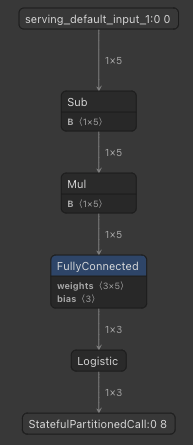
BTW, regarding the signature runners, can I pass the model file directly to the constructor of Interpreter as indicated by the documentation from the link you provided? Android Studio marked this as an error when I tried it.
@George_Soloupis, I updated the model in the project that I had shared with you, changed features back to 5 elements, and the model generated 3 outputs. However, the values are [0, 0, 255], instead of [30.668777, 111.0412 , 69.47372], as shown in the Colab notebook. It seems that the translation from the sigmoid activation function from h5 to the Logistic layer in tflite may be the reason for the discrepancy. If this is indeed the case, what should I do to correct it?
I have updated the tarball of the project to include the new tflite model file. Please let me know what I may have missed.
Thanks,
George
Hi @George_Soloupis and @markdaoust,
I think I have found the solution to the issue I had above. I was able to extend https://medium.com/analytics-vidhya/running-ml-models-in-android-using-tensorflow-lite-e549209287f0 to a 5 input and 3 output lr model and got the desired results.
Regards,
George
1 Like