Why does the performance of deeper ViTs saturate on relatively smaller datasets? Architectures such as ResNets don’t suffer from this issue that much. Can we separate class attention from the self-attention stage from the patches thereby inducing a form of cross-attention?
CaiT (Going Deeper with Image Transformers) answers all these questions and provides solutions.
In my latest project, I implement the CaiT family of models with the pre-trained parameters from the official CaiT codebase. They have been evaluated on the ImageNet-1k validation set for correctness. The highest top-1 accuracy is 86.066% (only trained on ImageNet-1k).
Code, models, interactive demos, notebooks for fine-tuning, off-the-shelf inference are here
Additionally, this Vision Transformer uses the Talking Head attention. So, this project could serve as a reference for the TF implementation of that.
Saliency
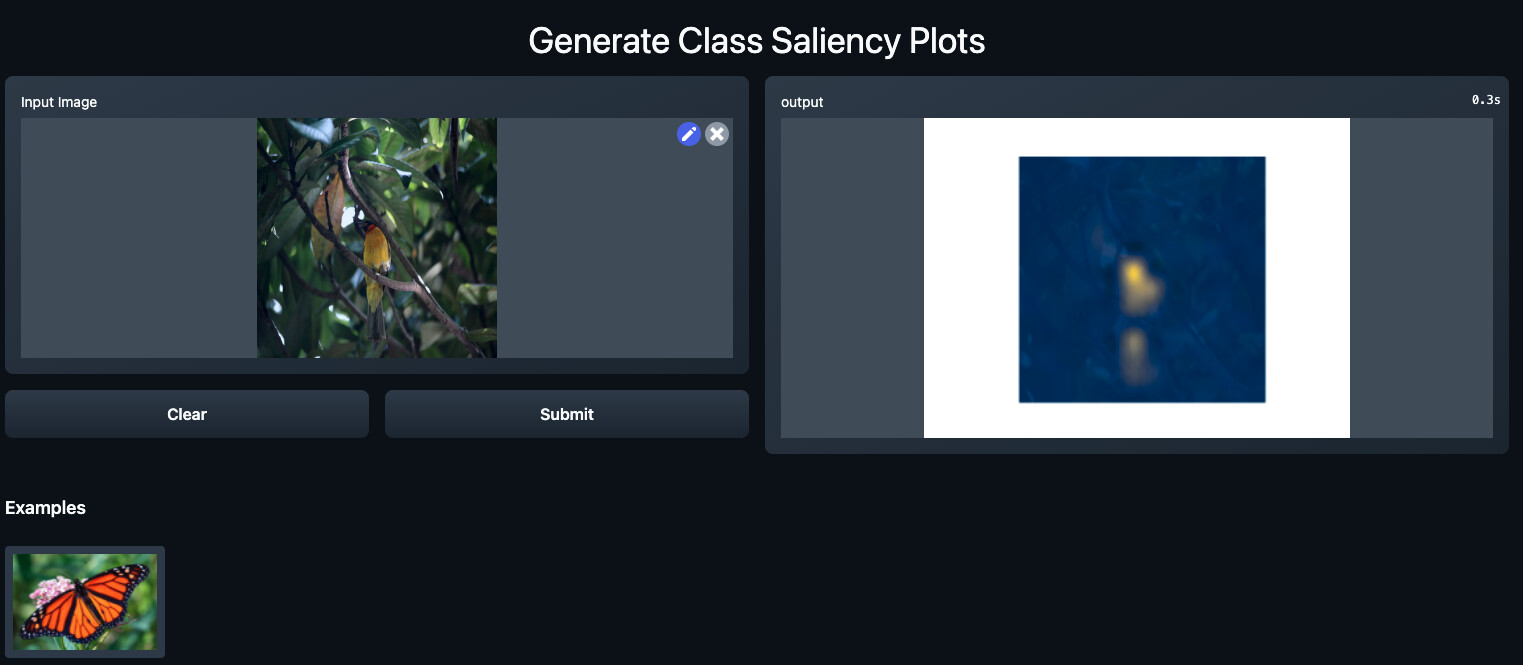
Spatial-class relationships
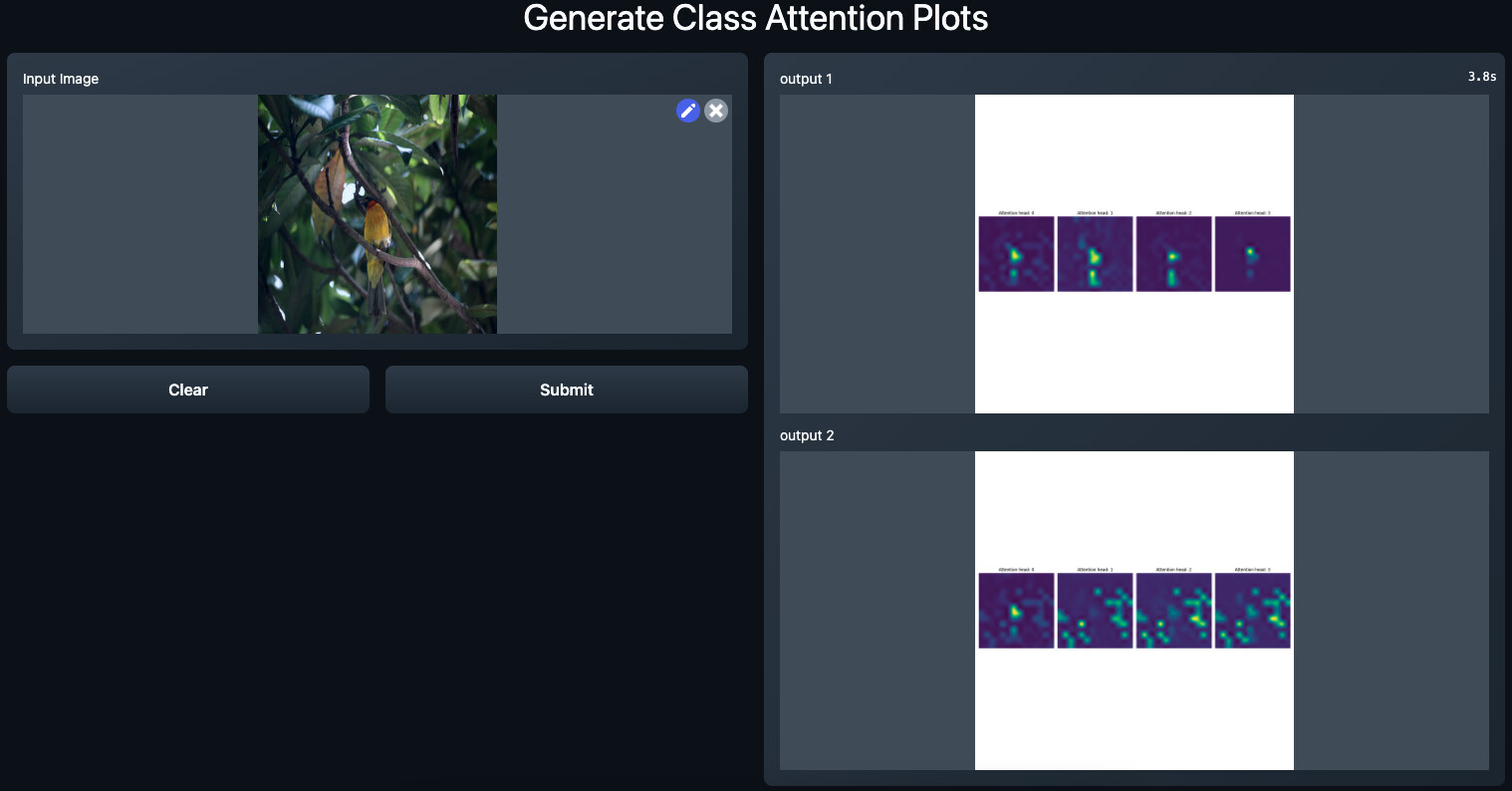
Check out the demos on Hugging Face Spaces: