I am trying to implement a WGAN loss function with Gradient Penalty on TPU. After training, the result is not what I expected it to be.
Below is the graph
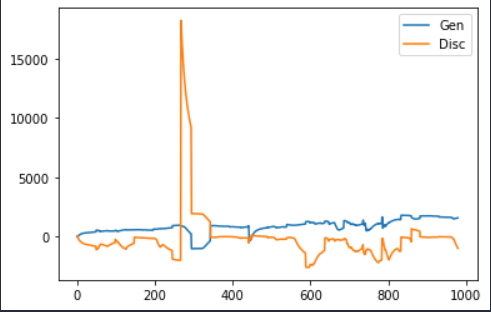
So,What I expected:
-
I expected a continuous decrease in both Generator and Discriminator loss.
-
The values should have been under a certain limit.
My code for the Generator and Critic(Discriminator) Loss:
class CriticLoss(object):
""" Criric Loss
Args:
discriminator:Discriminator model
Dx: Output of the real images from discriminator
Dx_hat: Output of the generated images(fake) from discriminator
x_interpolated:combined fake and real images
"""
def __init__(self, gp_lambda=10):
self.gp_lambda = gp_lambda
def __call__(self,discriminator, Dx, Dx_hat,x_interpolated):
#orgnal critic loss
d_loss = tf.reduce_mean(Dx_hat) - tf.reduce_mean(Dx)
#calculate gradinet penalty
with tf.GradientTape() as tape:
tape.watch(x_intepolated)
dx_inter = discriminator(x_interpolated, training=True)
gradients=tape.gradient(dx_inter, [x_interpolated])[0]
grad_l2 = tf.sqrt(tf.reduce_sum(tf.square(gradients), axis=[1, 2, 3]))
grad_penalty = tf.reduce_mean(tf.square(grad_l2 - 1.0))
#final discriminator loss
d_loss += self.gp_lambda * grad_penalty
return d_loss
#Generator loss
class GeneratorLoss(object):
""" Generator Loss """
def __call__(self,Dx_hat):
return tf.reduce_mean(-Dx_hat)
Since, I already checked my DCGAN model with CrossEntropy Loss and It works perfectly fine.So my model is not in fault here.It could be the fact that how TPU distribution strategy works and the loss functions calculated in the individual TPU device might not adding up to provide suitable values.
Also, I should point out that the loss values in the graph are calculated in the following way.
gen_loss.update_state(g_loss * tpu_strategy.num_replicas_in_sync)
disc_loss.update_state(d_loss * tpu_strategy.num_replicas_in_sync )
where gen_loss and disc_loss are defined as tf.keras.metrics.Mean() inside tpu_strategy.scope() while g_loss and d_loss are the output values from the GeneratorLoss and CriticLoss repsectively in the step_fn