Hi, I’m trying to create a multiclassification model to predict a particular bird species using a real world dataset of the following images that were submitted by the public. It consists of roughly 33,000 images very similar to the following.
Image 1:
Image 2:
Image 3:
Image 4:
Image 5:
Image 6:
Image 7:
Image 8:
Image 9:
Image 10:
Image 11:
Image 12:
Image 13:
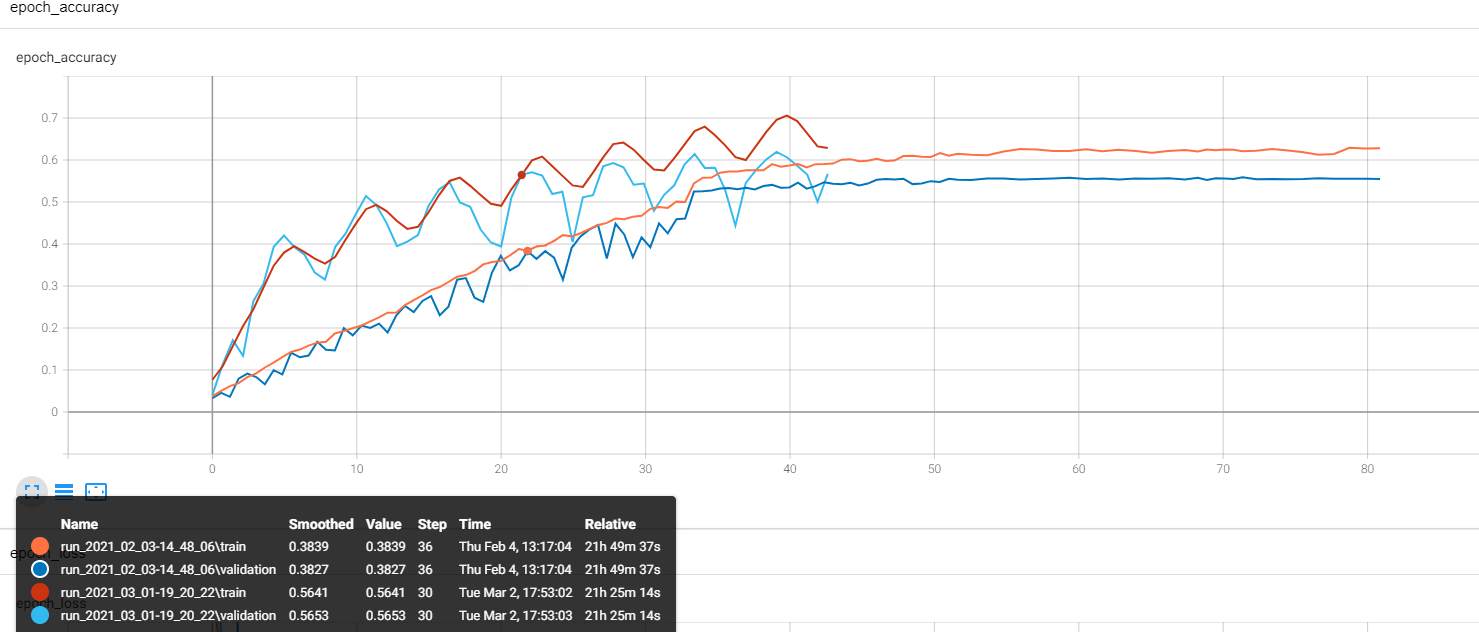
The problem I’m having is that my model is incapable of getting an accuracy beyond ~58% on the training dataset, beyond which is starts to flatten out as shown here:
I also applied a cyclical learning rate but to no avail as shown above. So, I used transfer learning particularly InceptionV3 and MobileNet and the validation accuracy still didn’t improve beyond my own model. So, I went back to look at the data. From your experience from looking at the above images, which range from a max resolution of 4347x3260 to 512x512, do you think I need to clean the dataset by removing some of the images and cropping out parts of the images?
Thanks
Thanks, I’ll go through that and see how I get on. The dataset I have consists of 33 different species of birds roughly 1000 images of each species where the image quality is similar to the above. I thought the problem was that when the images were being reduced the birds in the distance were becoming too low in resolution so I was thinking of deleting those ones and cropping some of the birds out of the high resolution images before reducing them in size for the model. But it’s very time consuming.
I think that when you have the annotated bounding boxes of the target you can have more flexible solutions about the resolution and you can have more specific augmentation specially if your dataset is small (33 classes over 1000 images it doesn’t seems to me too rich).
But you first goal now is still to achieve a decent overfit of your train dataset.
Sorry, I meant I have 1000 images of each of the 33 species resulting in 33,000 images. I thought that was plenty as I ran a similar bird identification model using the following Kaggle 270 species dataset and received an validation accuracy of 94%.
So I looked over that data and the difference between mine was each of those images were of single bird species whereas mine were from a distance, more than one bird in each image etc.
Thanks, I’ll go through that tutorial and see if there is much improvement.