I used to train my Xception-based CNN with Keras, which gave me the following val. acc. learning curve:
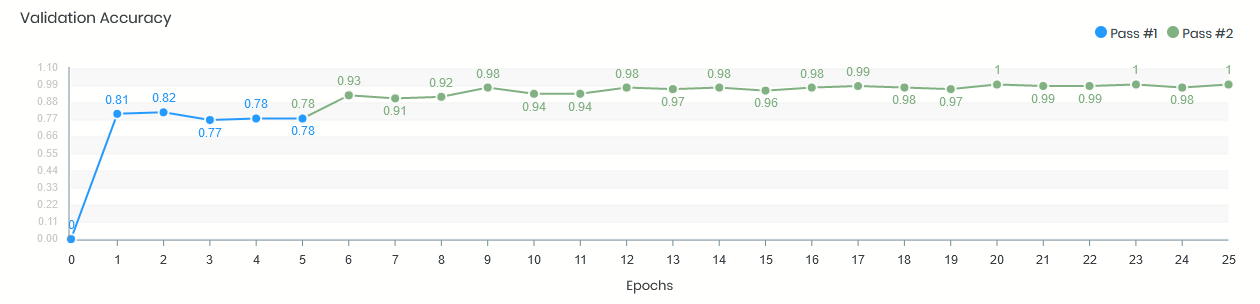
In the (blue) first pass only my custom model head was trained, then in the (green) second pass the whole model. Training was based on Keras ImageDataGenerator. As you can see here the model converged quite early during training, from the first epoch we got up to 80% val. acc., then with the 2nd training pass up to 90% until we soon achieved 99% and more. All was fine.
Now we got a new server, with four GPUs, so I changed the code to a) use a tf.distribute.MirroredStrategy() for multi-GPU training, and b) changed our input pipeline to tf.data.TFRecordDataset datasets. Now the model trains like this:
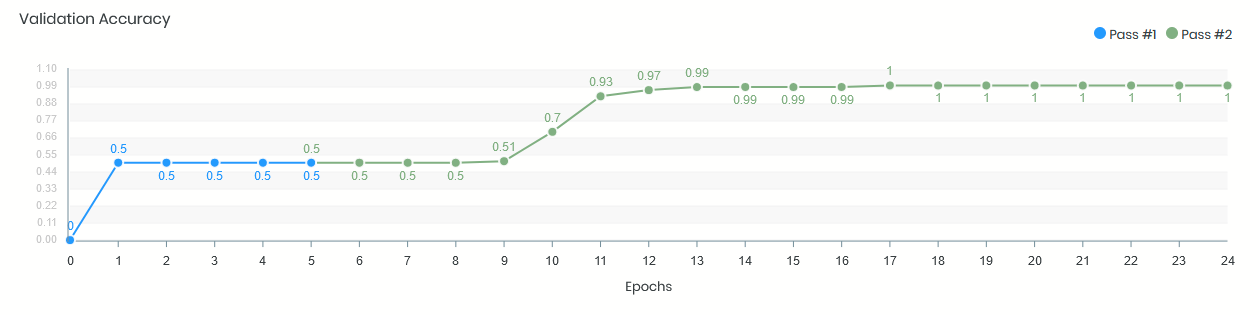
Note that except changing to TF datasets everything is still the same - the base model, our custom head, all activation functions, learning rate and optimizer. We literally did not change a bit in the model or training hyperparameters. However, as you can see the val. acc. training curve looks quite different now - the whole first pass and a few epochs in the second pass the val. acc. stays at 50%, then it rises up to 99% again.
Do you have any ideas why the model trains like this now, in particular why it sticks to 0.5 val. acc. for so many epochs, only to go up then later?
Here are the first 15 epochs:
Epoch 1/5
109/109 [==============================] - 38s 219ms/step - loss: 0.6077 - accuracy: 0.7375 - val_loss: 1.4544 - val_accuracy: 0.4965
Epoch 2/5
109/109 [==============================] - 21s 196ms/step - loss: 0.9669 - accuracy: 0.5070 - val_loss: 1.0026 - val_accuracy: 0.4972
Epoch 3/5
109/109 [==============================] - 21s 192ms/step - loss: 0.8568 - accuracy: 0.4953 - val_loss: 0.8937 - val_accuracy: 0.4965
Epoch 4/5
109/109 [==============================] - 21s 198ms/step - loss: 0.8218 - accuracy: 0.4906 - val_loss: 0.8239 - val_accuracy: 0.4967
Epoch 5/5
109/109 [==============================] - 21s 193ms/step - loss: 0.7843 - accuracy: 0.4946 - val_loss: 0.8551 - val_accuracy: 0.4970
Epoch 1/45
109/109 [==============================] - 90s 546ms/step - loss: 0.5002 - accuracy: 0.8162 - val_loss: 1.3786 - val_accuracy: 0.4982
Epoch 2/45
109/109 [==============================] - 56s 516ms/step - loss: 0.7800 - accuracy: 0.6433 - val_loss: 0.7703 - val_accuracy: 0.4987
Epoch 3/45
109/109 [==============================] - 55s 510ms/step - loss: 0.4577 - accuracy: 0.7694 - val_loss: 0.7968 - val_accuracy: 0.4975
Epoch 4/45
109/109 [==============================] - 57s 521ms/step - loss: 0.3059 - accuracy: 0.8670 - val_loss: 0.6995 - val_accuracy: 0.5060
Epoch 5/45
109/109 [==============================] - 58s 530ms/step - loss: 0.1744 - accuracy: 0.9375 - val_loss: 0.4394 - val_accuracy: 0.7046
Epoch 6/45
109/109 [==============================] - 57s 521ms/step - loss: 0.0916 - accuracy: 0.9776 - val_loss: 0.1951 - val_accuracy: 0.9322
Epoch 7/45
109/109 [==============================] - 57s 523ms/step - loss: 0.0472 - accuracy: 0.9918 - val_loss: 0.0922 - val_accuracy: 0.9738
Epoch 8/45
109/109 [==============================] - 58s 528ms/step - loss: 0.0264 - accuracy: 0.9962 - val_loss: 0.0478 - val_accuracy: 0.9887
Epoch 9/45
109/109 [==============================] - 57s 520ms/step - loss: 0.0156 - accuracy: 0.9982 - val_loss: 0.0327 - val_accuracy: 0.9940