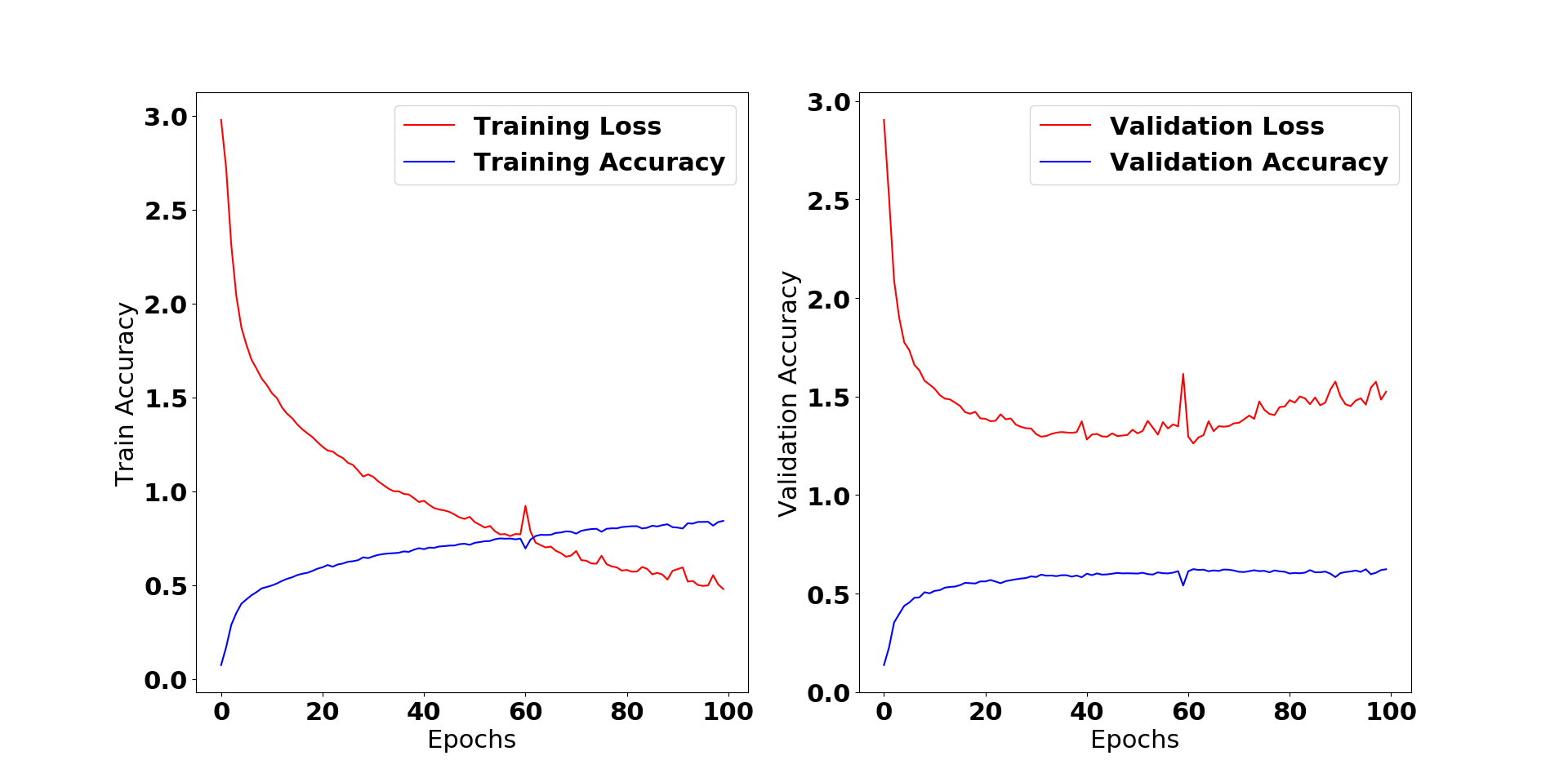
I am trying to train a model over human skeleton data and was able to achieve good accuracy overtraining but the validation loss reaches a point and starts to increase again. Model validation accuracy doesn’t decrease over time. Clearly, it overfitting and I totally understand. For reducing this I tried most of the techniques but was not able to decrease the validation_loss. I had tried dropouts, reducing model capacity, and adding loss for layers but no luck.
Log graph would be seen below
I don’t know your dataset but If you cannot collect more train data to cover your validation distribtuion you can try with some interesting augmentation approach like:
I am using the NTU-RGBD dataset for training. According to your idea what should be validation distribution. My dataset size is around 18000 samples and split 80:10:10. Also model parameters is around 210,864.