Thanks for your input i will check it out
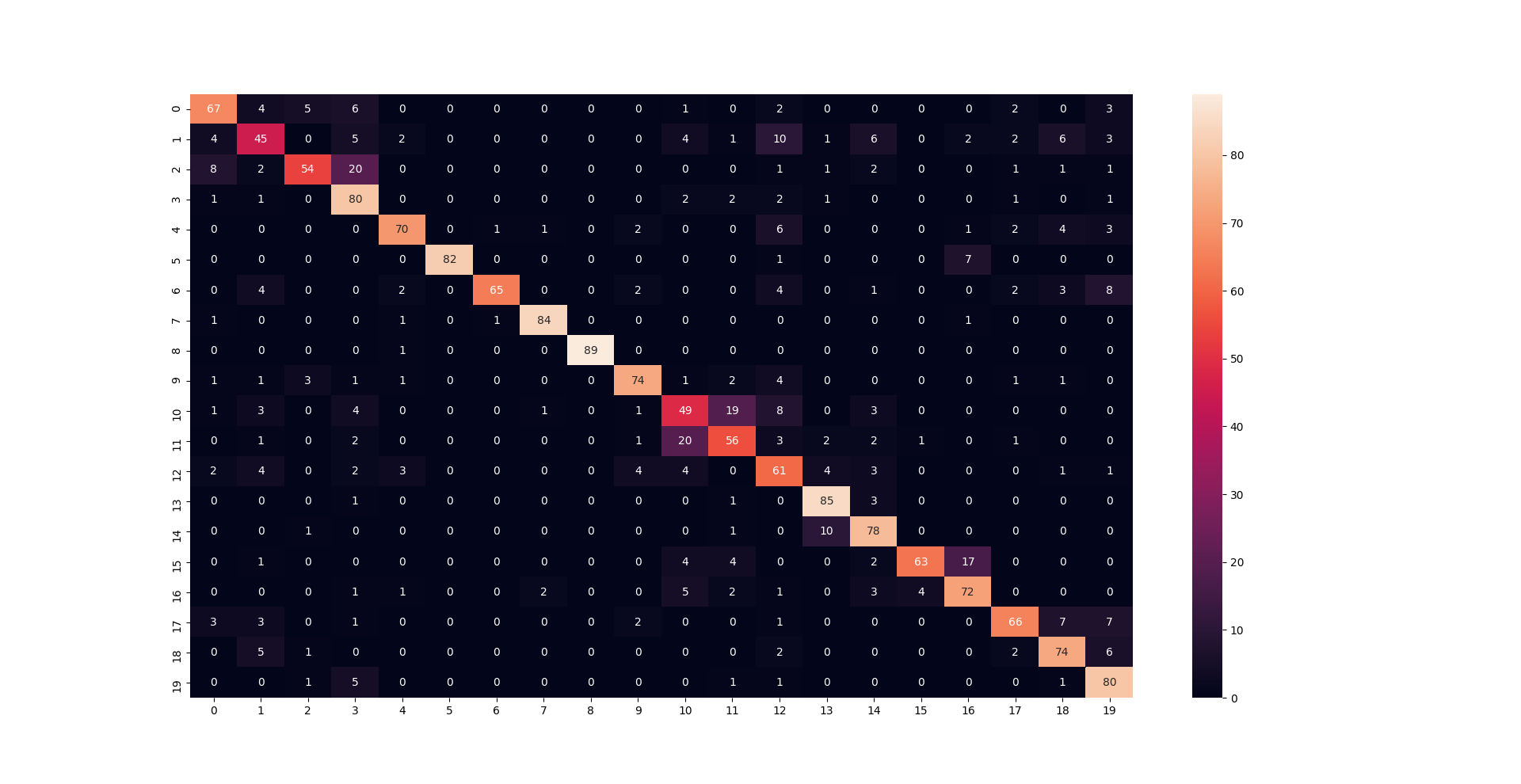
It seems that there is enough confusion between 2 and 3 and 10 and 11 classes.
precision recall f1-score support
0 0.76 0.74 0.75 90
1 0.61 0.49 0.55 91
2 0.83 0.59 0.69 91
3 0.62 0.88 0.73 91
4 0.86 0.78 0.82 90
5 1.00 0.91 0.95 90
6 0.97 0.71 0.82 91
7 0.95 0.95 0.95 88
8 1.00 0.99 0.99 90
9 0.86 0.82 0.84 90
10 0.54 0.55 0.55 89
11 0.63 0.63 0.63 89
12 0.57 0.69 0.62 89
13 0.82 0.94 0.88 90
14 0.76 0.87 0.81 90
15 0.93 0.69 0.79 91
16 0.72 0.79 0.75 91
17 0.82 0.73 0.78 90
18 0.76 0.82 0.79 90
19 0.71 0.90 0.79 89
accuracy 0.77 1800
macro avg 0.79 0.77 0.77 1800
weighted avg 0.79 0.77 0.77 1800
Have you tried to shuffle the samples between the train and validation on the classes where you have the lowest performance? Have you tried to manually inspect some of these samples?
Are these specific classes also hard in the reference papers results that I’ve mentioned above?
- Shuffle yes have done for both.
- yes
- Classes with more confusion are
[ eat meal/snack, brushing teeth, reading, writing]
[1,2,10,11] - index refer to confusion matrix.
Also, my approach is different. I am trying to achieve more accuracy with minimal preprocessing. So I have considered only skeleton data as input.
By the name of classes it seems to be hard to classify.
Also, my approach is different. I am trying to achieve more accuracy with minimal preprocessing. So I have considered only skeleton data as input.
I think many methods there are skeleton only, e.g.:
https://arxiv.org/abs/2104.13586
1 Like
Thanks for your inputs will try to added these additional methods.