Hi, I am working on a project where I am trying to predict JEL codes from abstracts.
Recently, I’ve been adapting the code from this example provided by Sayak Paul and Soumik Rakshit, where they built a multi-label text classifier that predicts the subject areas of arXiv papers based on their abstract bodies.
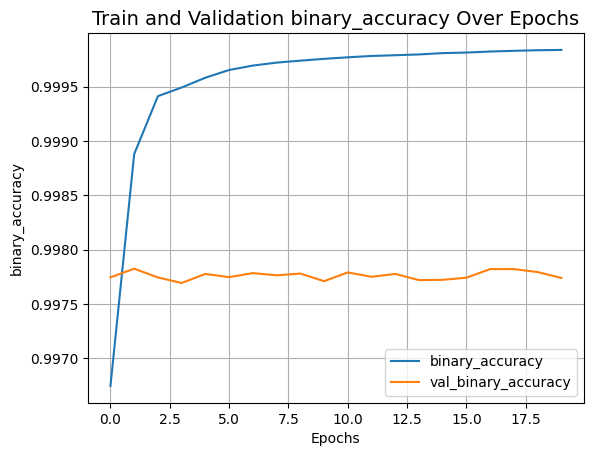
However, as I’ve been tailoring their code to my needs, I’ve encountered an intriguing issue regarding the model’s performance metrics. From the training logs of the original model, and in my adaptation, the validation loss seems to increase with each epoch. Conventionally, this trend suggests overfitting. Yet, the model performs admirably on the test set, in both the original example and my project (+99% in my case).
I’ve attached screenshots of my model’s performance metrics for your reference. I am looking to understand this phenomenon. Is the increasing validation loss indeed indicative of overfitting, or am I potentially misinterpreting some aspect of the model’s performance?
I would greatly appreciate any insights or suggestions that the community can offer on this matter. Thank you for your time.