Greetings of the day!!!
I am working on text classification model from TFLITE (BERT_TFLITE). During inferencing the model in REST API, it is consuming 100 % memory of Azure Virtual Machine. The configurations of VM is given below: Virtual Machine RAM : 32 GB Swap Memory size: 16 GB Memory size: 64 GB Number of cores : 4
When I am providing some list of text from databases to TFLITE model, after some time when model loaded into memory it started consuming the VM to 100% and after some time either API is crashing or it goes into the hang mode. Sometimes it works well but this issue is coming most frequently.
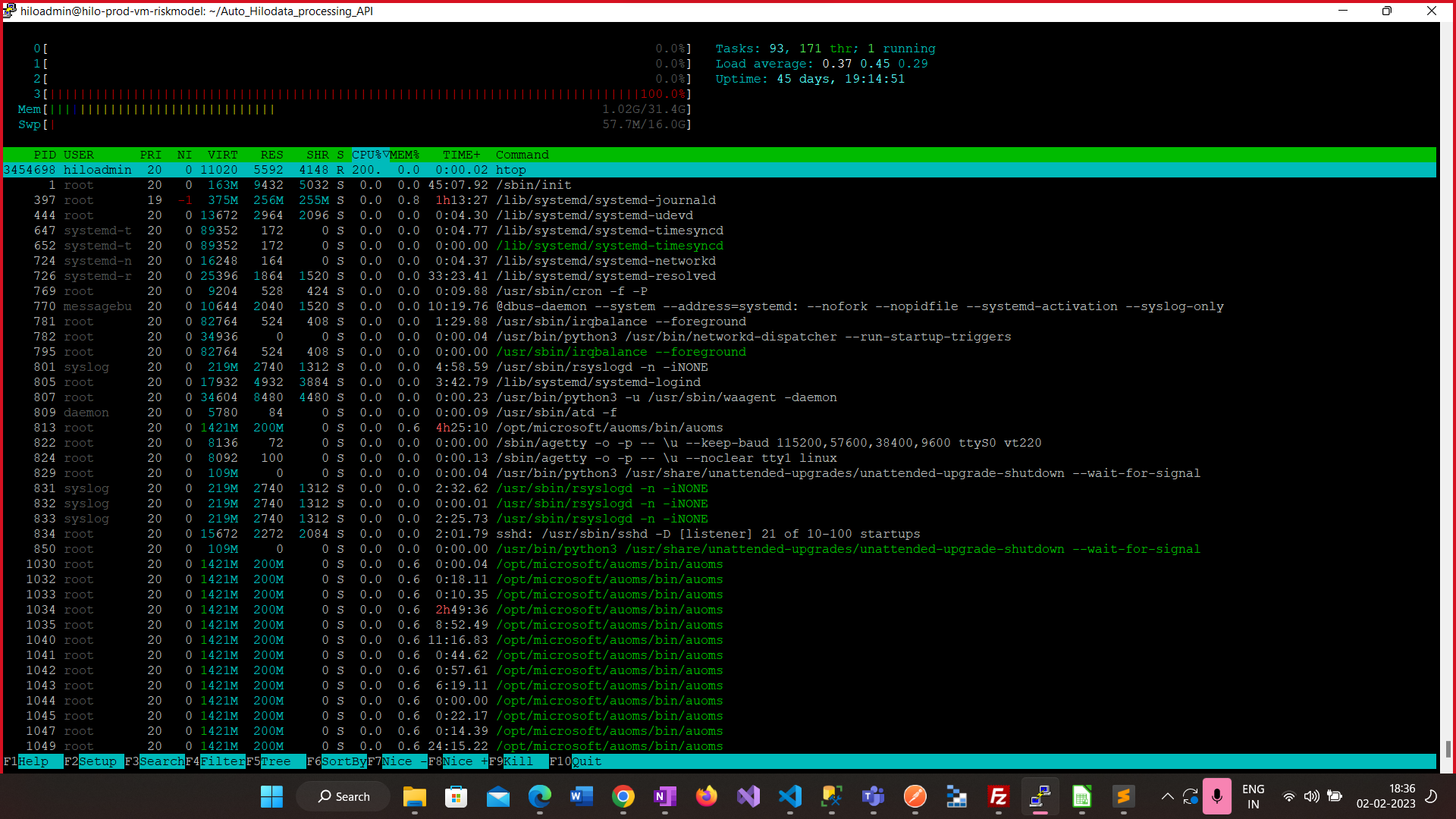
For your reference I am sharing the screenshot of CPU Utilization of VM:
The codes that I am using to inference a model on given text is given below:
#This description list contains some text sentences of length of 100 words maximum
for i in range(len(description_list)) :
# sentence= "During cargo hold cleaning after discharging of Sulphur cargo in bulk, smoke was noticed from the cargo residue on tank top of cargo hold Nr. 3. Crew "
output= prepare_features(description_list[i])
output1= output['input_ids']
encoded_results= np.asarray(output1, dtype=np.int32) # here coverting the text into the numpy array as per model signature
# print(encoded_results)
a= np.expand_dims(encoded_results, axis=0)
interpreter = tf.lite.Interpreter(model_path="model.tflite")
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
check_interpreter=True
interpreter.set_tensor(input_details[0]['index'], a) # setting the encoded numpy array into the model
interpreter.invoke()
output_details = interpreter.get_output_details()
output_data = interpreter.get_tensor(output_details[0]['index'])
model_result= output_data.tolist() # Converted the model output into a list
For your reference, I am also providing the model signature which i used during training of this model:
batch_size= 128
max_seq_length=128
Note: The model is working fine and giving good accuracies but question is why it is consuming 100% CPU everytime even with small data this problem is coming frequently and most of the time it hangs the API on VM for sometime and this is a TFLITE model so ideally it should consume less CPU because training parameters are less and model size is also less.
Is there any way to optimize this model, so that it will consume less CPU.
Please let me know in case of any more information is required. Any Quick help is appreciated.
What I’d try first is (just a guess!!!):
stop allocating tensors inside the for loop.
do it outside and only use set_tensor inside the loop to set the input for the model.
also the following lines after the set_tensor can stay inside the loop
Thanks for your quick help. I have tried to allocate the tensors out of the loop still the same memory leak problem is coming.
There is also Another problem that I noticed which looks very weired to me is:
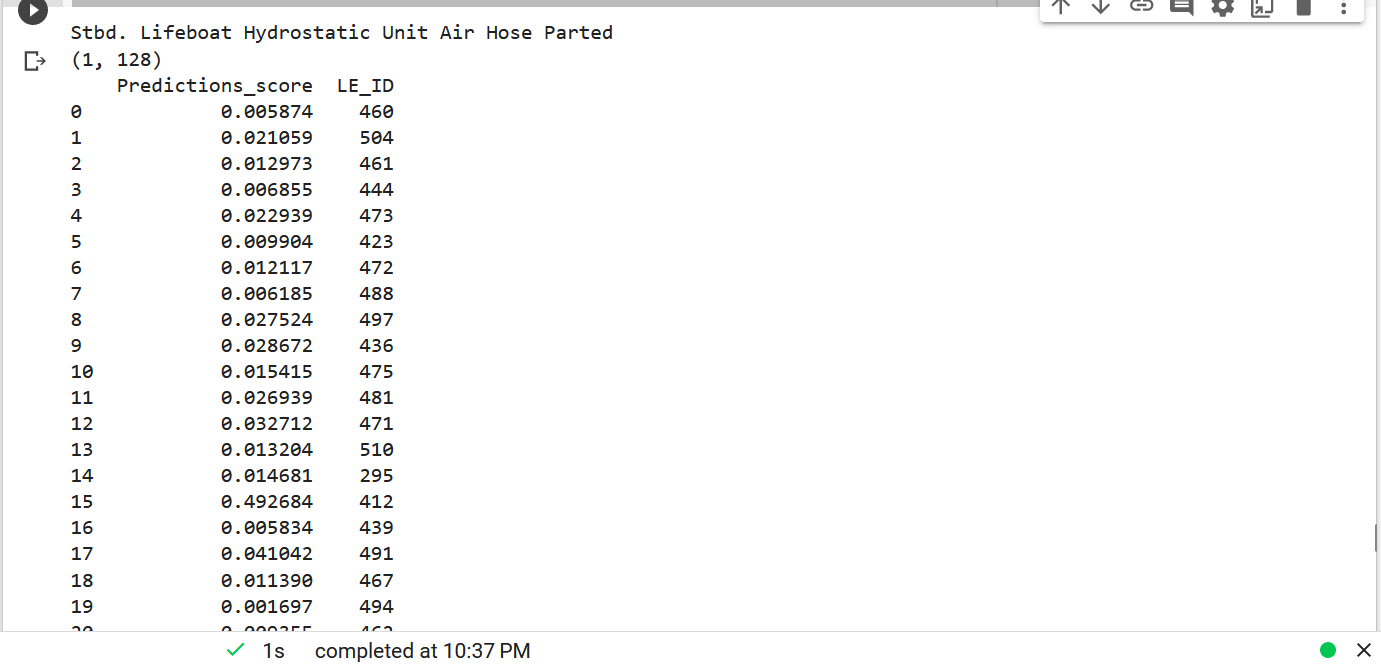
When I am inferencing the model on any text sentence most of time it is working fine but sometimes it is giving me this error which is given below in the screenshot:
Strange things is when i just re run the model the problem is not coming. This is a random issues. I tried 5 times on the same sentence but out of 5 times 2 times this error comes.
The codes are give below:
Note: For your reference, On the same sentence when I rerun the model it is working fine the output is given below on the same sentence without any change in the codes:
As the screenshot shows there is no problem at code side or model
This random issue is actully causing the API to stop working. Is this a internal bug. Can you please help or suggest some ways to resolve it.
Yes Igsum with the same sentence, I am getting different results and sometimes getting the mentioned errors. The errors are coming randomly on the same sentence.
Yeah you are absolutely right, becuase in normal tensorflow models I have never faced these such issues. Is it due to some internal bugs in TFLITE, maybe the issue is something related to embeddings, i think embeddings are different. Whats your thought on this and is there any solution or should I move to normal tensorflow classification model?
does the model pre tflite conversion show any random behavior?
how did you convert it? (eg: cmd line paramenters)
I don’t know if it’s a tflite bugs, lot’s of moving pieces but if the original model behaves properly, maybe create a github issue against tflite
of course that would need some simple code to reproduce the issue
I have trained this model using TFLITE library and not used any conversion techniques. The training codes of my Model is given below:
from tflite_model_maker.text_classifier import DataLoader
from tflite_model_maker import configs
training= traindata.to_csv(’/content/train_LE.csv’,index=False)
testing= testdata.to_csv(’/content/test_LE.csv’, index=False)
spec = model_spec.get(‘bert_classifier’)
train_data = DataLoader.from_csv(
filename=’/content/train_LE.csv’,
text_column=‘Cleaned_text’,
label_column=‘LeadingEventID’,
model_spec=spec,
is_training=True)
test_data = DataLoader.from_csv(
filename=’/content/test_LE.csv’,
text_column=‘Cleaned_text’,
label_column=‘LeadingEventID’,
model_spec=spec,
is_training=False)
model = text_classifier.create(train_data, model_spec=spec, epochs=4,batch_size=64)
model.summary()
loss, acc = model.evaluate(test_data)
model.export(export_dir=’/content/drive/MyDrive/rohit_datasetLE_bert_classifier/’)
I just used the TFLITE documentation to train this model.
But yeah I will create a github issue against tflite
Thanks