MLP-Mixer: An all-MLP Architecture for Vision (Tolstikhin et al., 2021) (Google)
Convolutional Neural Networks (CNNs) are the go-to model for computer vision.
Recently, attention-based networks, such as the Vision Transformer, have also
become popular. In this paper we show that while convolutions and attention are
both sufficient for good performance, neither of them are necessary. We present
MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs).
MLP-Mixer contains two types of layers: one with MLPs applied independently to
image patches (i.e. “mixing” the per-location features), and one with MLPs applied
across patches (i.e. “mixing” spatial information). When trained on large datasets,
or with modern regularization schemes, MLP-Mixer attains competitive scores on
image classification benchmarks, with pre-training and inference cost comparable
to state-of-the-art models. We hope that these results spark further research beyond the realms of well established CNNs and Transformers.
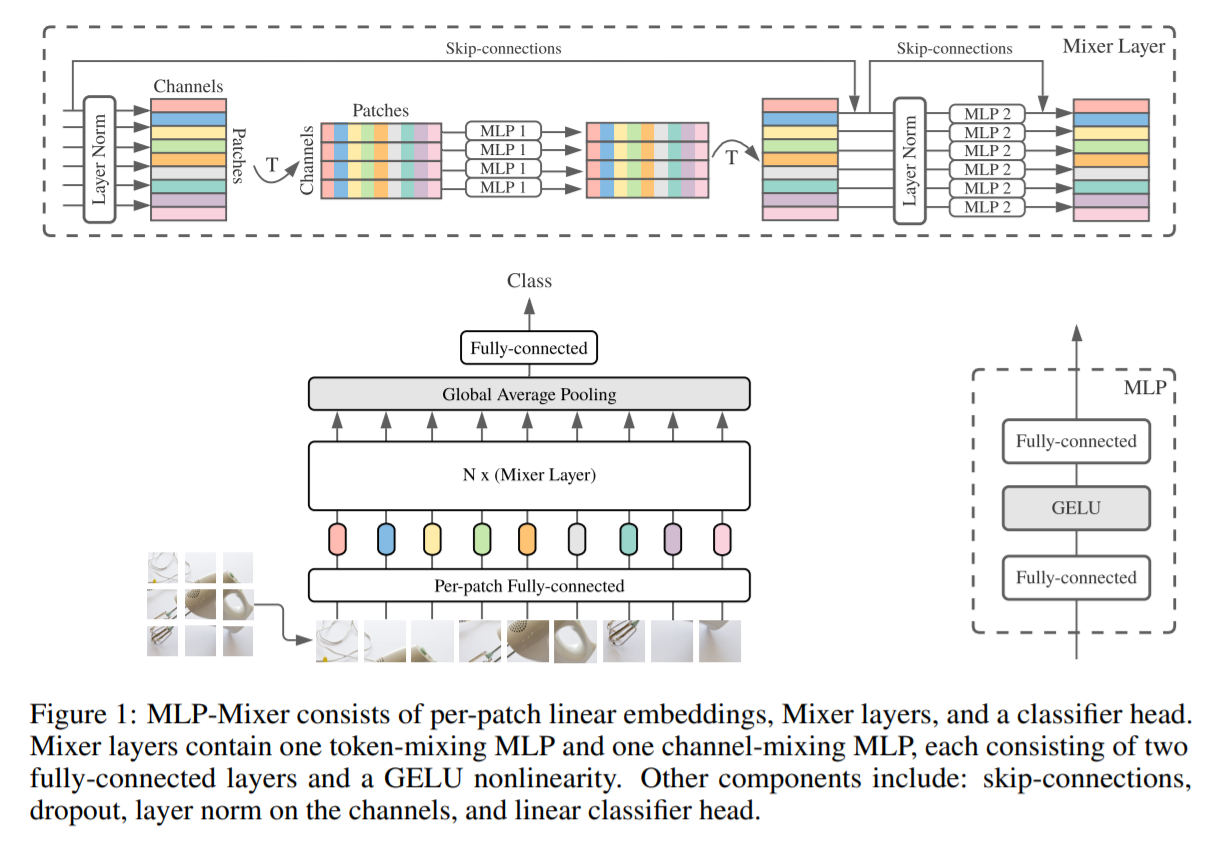
… our architecture can be seen as a very special CNN, which uses 1×1 convolutions
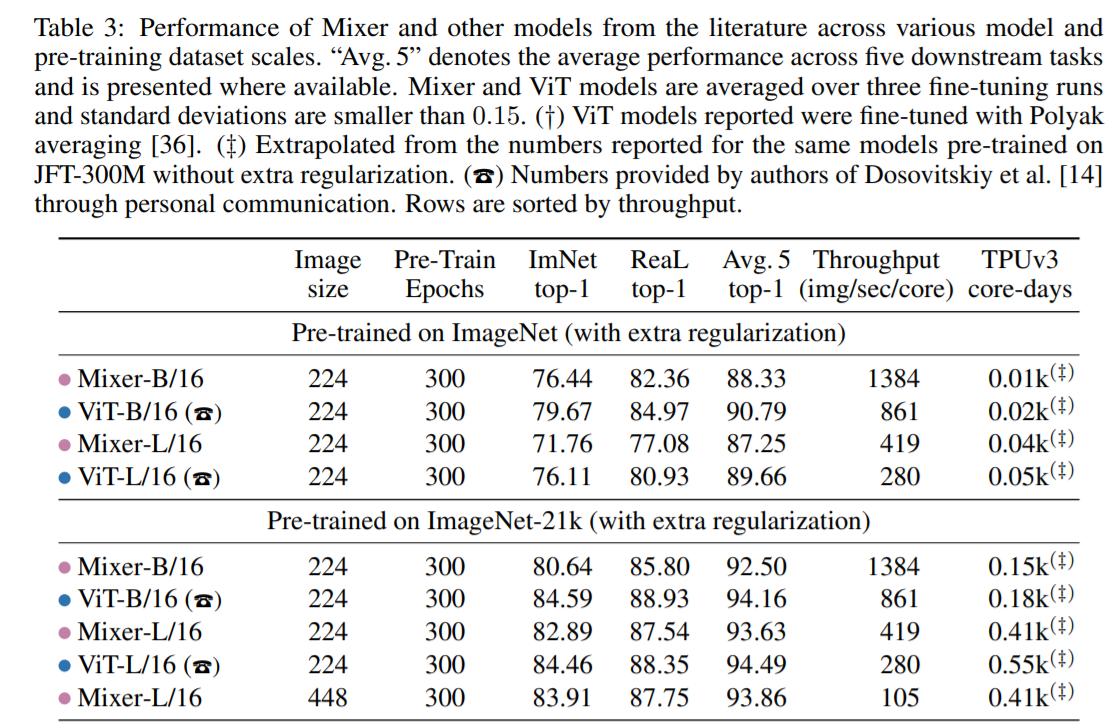
for channel mixing, and single-channel depth-wise convolutions of a full receptive field and parameter sharing for token mixing. However, the converse is not true as typical CNNs are not special cases of Mixer. Furthermore, a convolution is more complex than the plain matrix multiplication in MLPs as it requires an additional costly reduction to matrix multiplication and/or specialized implementation.Despite its simplicity, Mixer attains competitive results. When pre-trained on large datasets (i.e., ∼100M images), it reaches near state-of-the-art performance, previously claimed by CNNs and Transformers, in terms of the accuracy/cost trade-off. This includes 87.94% top-1 validation accuracy on ILSVRC2012 “ImageNet” [13]. When pre-trained on data of more modest scale (i.e., ∼1– 10M images), coupled with modern regularization techniques [48, 53], Mixer also achieves strong performance. However, similar to ViT, it falls slightly short of specialized CNN architectures.
We describe a very simple architecture for vision. Our experiments demonstrate that it is as good as existing state-of-the-art methods in terms of the trade-off between accuracy and computational resources required for training and inference. We believe these results open many questions. On the practical side, it may be useful to study the features learned by the model and identify the main differences (if any) from those learned by CNNs and Transformers. On the theoretical side, we would like to understand the inductive biases hidden in these various features and eventually their role in generalization. Most of all, we hope that our results spark further research, beyond the realms of established models based on convolutions and self-attention. It would be particularly interesting to see whether such a design works in NLP or other domains.
@Sayak_Paul’s implementation:
https://tensorflow-prod.ospodiscourse.com/t/mlp-mixer-with-cifar-10/1355?u=8bitmp3