Original vision transformers don’t provide multi-scale hierarchical representations of images. While this may not be a problem for tasks like image classification but dense prediction tasks like object detection, segmentation, etc. benefit from multi-scale representations.
Swin transformers introduce a sense of hierarchies by operating on windows of patches and then shifting the windows to induce connection between the windows. It uses a variant of multi-head attention with a linear complexity w.r.t the input image size. This makes Swin Transformers a better backbone for object detection, segmentation, etc. that require high-resolution inputs and outputs.
In my latest project, I implement 13 different variants of Swin Transformers in TensorFlow and port the original pre-trained parameters into them. Code, pre-trained TF models, notebooks, etc. are available here:
The project comes with TF implementations of window self-attention, and shifted-window self-attention that introduce linear time complexity in Swin Transformers allowing them to scale to larger image resolutions.
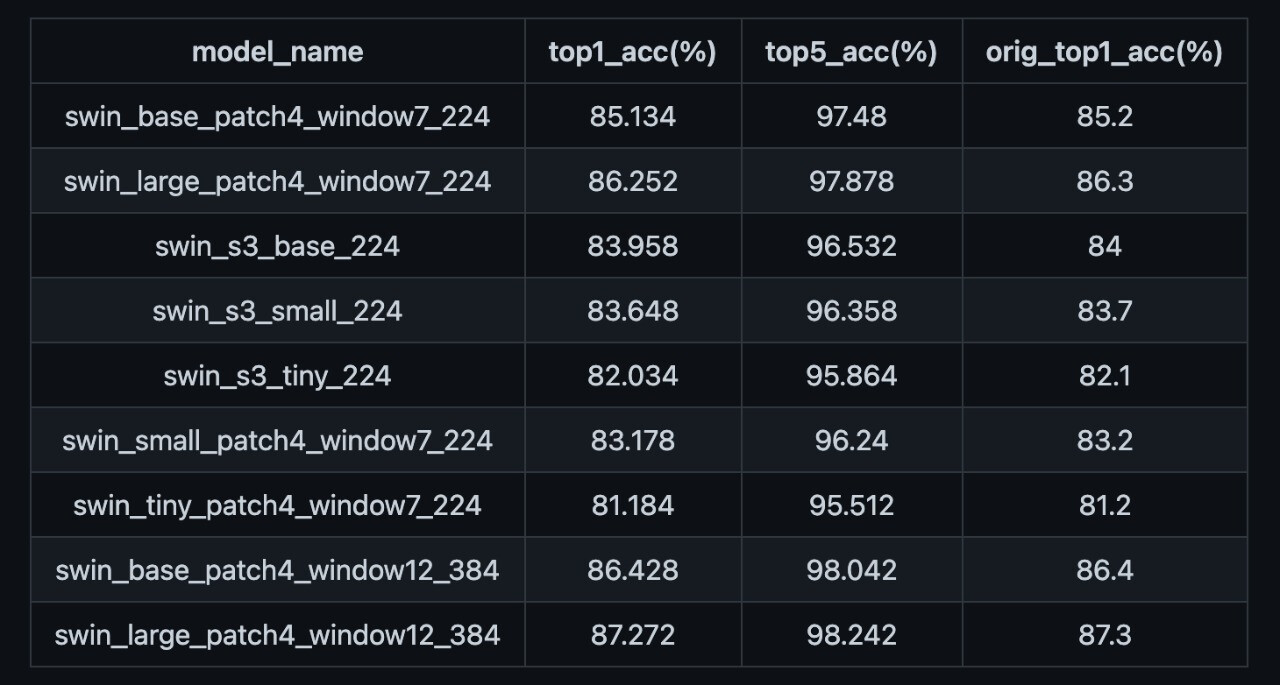
The ported models have been verified to ensure they match the reported performance: