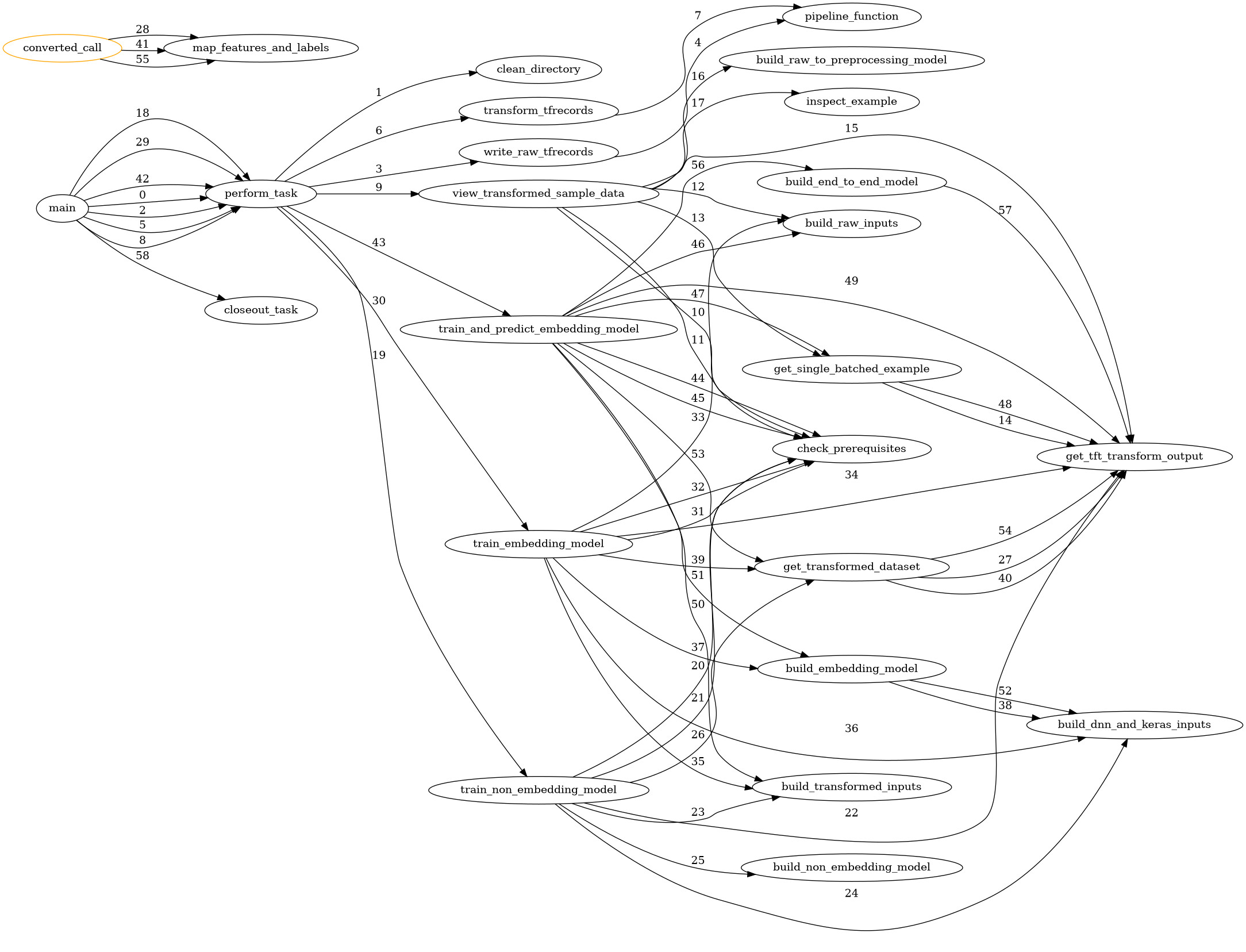
I would like to get some feedback on a project I’ve been working on: tft_tasks. The picture below was produced by using trace_path.py, also from this project. The third column of nodes are the tasks provided by tft_tasks and the other nodes are the various python functions that make up these tasks.
My Goal
I think MLOPS is about making a leap in many different dimensions; the comfort and safety of pandas, numpy, scikit-learn, Jupyter notebooks, to the uncharted world of tensors, tensorflow transforms, model serving, etc. I think we need to make this leap easier, and it is my hope that something like tft_tasks can help, even if a little bit, by grounding users in the familiar reality of python. As such, I see this as a gateway project that gets users to adopt thinking that leads to “pipeline oriented thinking”.
If you look at the continuum of ML, on one side you have AutoML, and on the other side you have custom training with pipelines etc. I think there’s a middle-ground that can help people appreciate just how rich of an ecosystem tensorflow provides from a feature engineering perspective. For example, with tensorflow transform, if you write a preprocessing_fn in a certain way, you essentially get infinite scale with the dataflow model/apache beam.
Wouldn’t it be great if you could point to your data, and the tensorflow ecosystem provides you not only a starting point, where you could write your feature engineering component of the overall workflow, but also provides you with the connections into a basic model, and produces artifacts that can be served? That’s the goal that I’m working towards.
Where I am:
v0.02 Provides the following features:
- Sample implementation of an end-to-end ML pipeline in
tft_tasks.pyusing tensorflow transform including sample data. - Instrumentation and depiction of the “pipeline” via
TracePathintrace_path.pythat captures and visualizes the interrelationships amongst the various functions. The idea being to make the problem less daunting by breaking it down into pieces. Each node is a function, and the edges are transitions of control. For example, one of the tasks isview_transformed_data, where the user can see what a single observation looks like after it’s been passed throughpreprocessing_fn. - An extensible task based framework via
task_dagintft_tasks.pythat captures the dependencies among the various functions that comprise the pipeline, and handles executing pre-requisites. - Maintenance of task state via
task_state_dictionaryintft_tasks.pyso as not to repeat tasks that have already been performed. - Execution performance is captured, but not currently exposed directly to the user. Performance data is available in the
MyTracePathobject.
What’s next?
I want to make use of tfx to get the schema related information, and generalize this and add in some interactivity for tabular datasets. It would be a dream to be able to produce a Jupyter notebook to get people started/hooked into the amazing tensorflow ecosystem.
What I need?
I would love feedback through use, ideas, critique of the design/code. Pull requests and issues are also welcome at the repo. Thank you!