In a ViT setup, dividing an image of (256, 256) into patches of (8, 8) gets you 1024 patches to deal with.
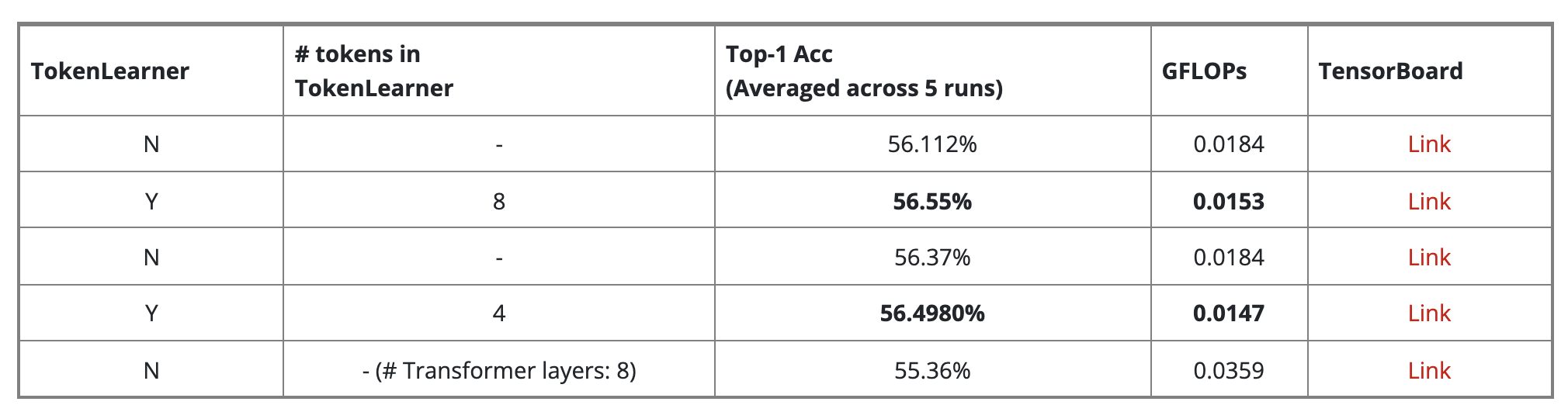
In our (w/ @Sayak_Paul) new keras example we implement Adaptive Space-Time Tokenization for Videos by Ryoo et. al. that helps reduce token count from 1024 to 8.

What makes it even more interesting is that there is no performance drop with reducing the number of tokens. The paper (and we in the example) report lesser FLOPs accompanying boost in downstream results.