I have a neural network, binary classifier, a couple of dense layers, a couple of ReLU layers, 10% dropout, etc.
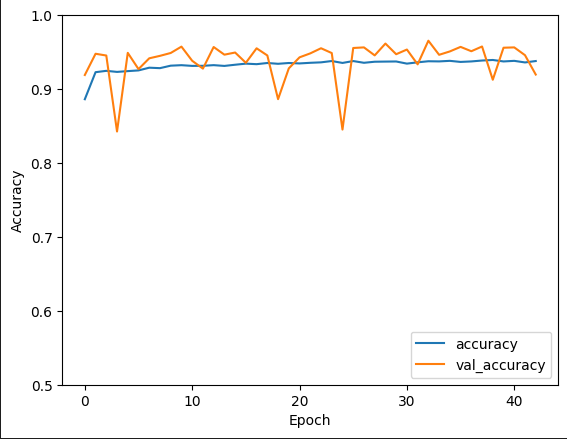
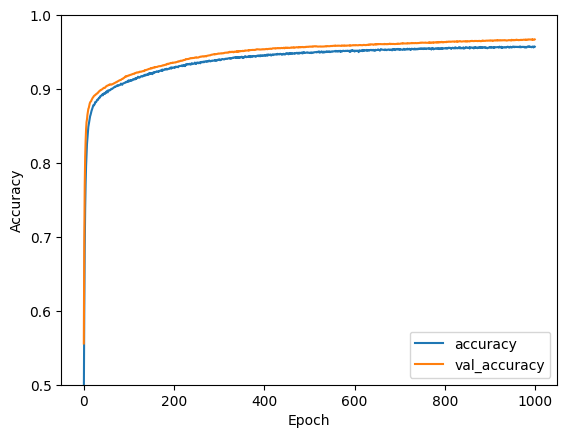
I’m looking at the accuracy curves from two different optimizers, SGD, or ADADELTA. I’m leaning toward using the ADADELTA model, but would love to hear your experiences and thoughts.
Second question: should I allow the ADADELTA to keep training? I have early stopping implemented, but it ran the full 1000 epochs. As can be seen, the SGD stopped after just over 40 epochs.
As far as your doubt is concerned here is what I think should be the answer.
So Adadelta here uses something called as an adaptive learning rate where, as the weights become more optimized over iterations we decrease the value of the learning rate in order to fine tune them. Where as for your classical implementation of SGD the learning rate remains constant throughout also SGD is slower than your adaptive optimizers for convergence another point that makes SGD difficult to use is to choose an appropriate learning rate.
The fluctuations you see in the graph is caused due to the data being passed in mini-batches. You could try and increase the batch size.
Despite the drawbacks of SGD there are papers that do argue that SGD generalizes much better than the adaptive optimizers and can actually perform better if provided good initial learning rate along with a learning rate scheduler.
There are also other adaptive optimizers you try like RMSProp, Adams etc. Among which adams is taken as a baseline optimizer as it combines RMSProp with momentum to be much faster.
Coming to your second question it seems that your graph has plateaued and no further training might be required.