Hello everyone,
I’ve implemented a so called ‘interaction network’ (a graph neural network) using tensorflow based on this paper: https://arxiv.org/abs/1612.00222. Here is a schematic of the architecture for my implementation:
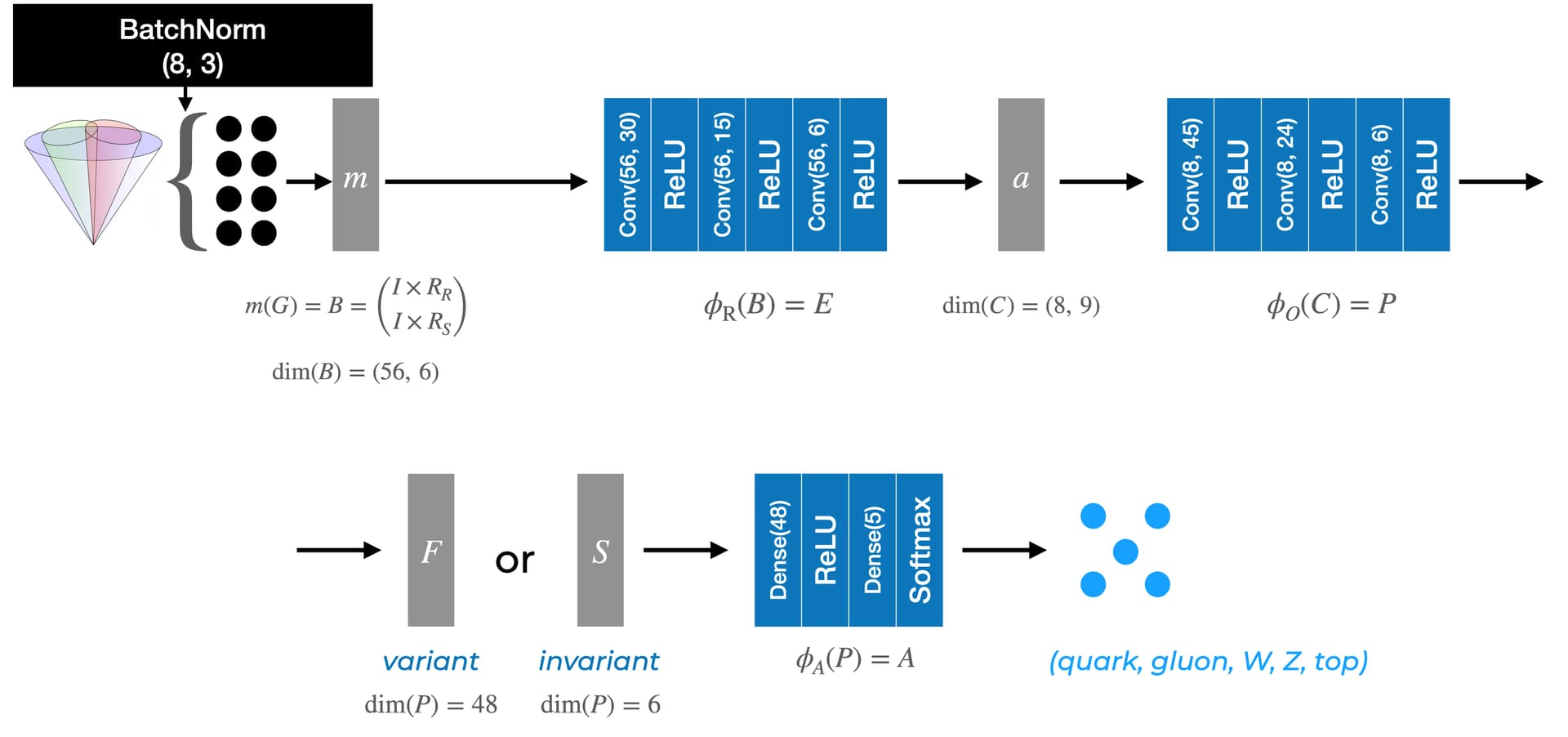
The training data consists of samples that each contain 8 constituents, and each constituent contains 3 features. These constituents are encoded in nodes in a graph. The network that uses a summation layer before phi_A is supposedly permutation invariant, i.e., the trained network should be the same no matter the order of the constituents within each sample.
However, I observe the following behaviour. I fix the tensorflow seed such that my training is determininstic. I also fix the order of my samples. Then, I shuffle the constituents of each sample using two different seeds (127 and 273), obtaining to different data sets. The network is permutation invariant. Thus, theoretically, training the network on these two different arrangements should give exactly the same results. However, after the first few hundred events, I observe that the gradients start to diverge between the two trainings, growing larger as the training goes on. This leads to significant differences at the end of the training.
Is this expected behaviour or am I observing some sort of bug?