The experimental environment is as follows:
System: Ubuntu 18.04.6 LTS
CPU: Intel(R) Core™ i5-12400
I have tried it on the following code:
import tensorflow as tf
import timeit
@tf.function(jit_compile=True)
def model_fn(x, y, z):
return tf.reduce_sum(x + y * z)
def model_fn1(x, y, z):
return tf.reduce_sum(x + y * z)
x=tf.random.uniform([100,100])
y=tf.random.uniform([100,100])
z=tf.random.uniform([100,100])
result1=model_fn1(x,y,z)
print ("NoXLA execution:", timeit.timeit(lambda: model_fn1(x,y,z), number=1000), "seconds")
result2=model_fn(x,y,z)
print ("XLA execution:", timeit.timeit(lambda: model_fn(x,y,z), number=1000), "seconds")
I tried different sizes of matrix. The experimental data are as follows:
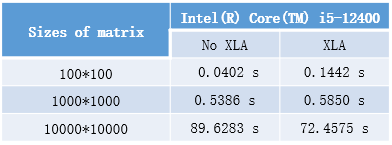
The runtime state is as follows:
100*100 :
2023-03-13 20:30:53.104299: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX_VNNI FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-03-13 20:30:53.184350: I tensorflow/core/util/port.cc:104] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2023-03-13 20:30:53.186470: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2023-03-13 20:30:53.186482: I tensorflow/compiler/xla/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
2023-03-13 20:30:53.569076: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory
2023-03-13 20:30:53.569117: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory
2023-03-13 20:30:53.569121: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
2023-03-13 20:30:53.894776: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory
2023-03-13 20:30:53.894792: W tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:265] failed call to cuInit: UNKNOWN ERROR (303)
2023-03-13 20:30:53.894801: I tensorflow/compiler/xla/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (nisl-System-Product-Name): /proc/driver/nvidia/version does not exist
2023-03-13 20:30:53.894973: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX_VNNI FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
NoXLA execution: 0.04019642301136628 seconds
2023-03-13 20:30:53.988749: I tensorflow/compiler/xla/service/service.cc:173] XLA service 0x1ddecc0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2023-03-13 20:30:53.988774: I tensorflow/compiler/xla/service/service.cc:181] StreamExecutor device (0): Host, Default Version
2023-03-13 20:30:53.990340: I tensorflow/compiler/xla/service/dump.cc:485] HloModule dump enabled with path prefix: , suffix: before_optimizations
2023-03-13 20:30:54.005466: I tensorflow/compiler/jit/xla_compilation_cache.cc:477] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
XLA execution: 0.14420688600512221 seconds
1000*1000 :
2023-03-13 20:34:22.639479: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX_VNNI FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-03-13 20:34:22.709338: I tensorflow/core/util/port.cc:104] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2023-03-13 20:34:22.711450: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2023-03-13 20:34:22.711461: I tensorflow/compiler/xla/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
2023-03-13 20:34:23.082472: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory
2023-03-13 20:34:23.082506: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory
2023-03-13 20:34:23.082509: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
2023-03-13 20:34:23.424403: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory
2023-03-13 20:34:23.424420: W tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:265] failed call to cuInit: UNKNOWN ERROR (303)
2023-03-13 20:34:23.424429: I tensorflow/compiler/xla/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (nisl-System-Product-Name): /proc/driver/nvidia/version does not exist
2023-03-13 20:34:23.424612: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX_VNNI FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
NoXLA execution: 0.53856693796115 seconds
2023-03-13 20:34:24.028637: I tensorflow/compiler/xla/service/service.cc:173] XLA service 0x1b146e0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2023-03-13 20:34:24.028673: I tensorflow/compiler/xla/service/service.cc:181] StreamExecutor device (0): Host, Default Version
2023-03-13 20:34:24.031584: I tensorflow/compiler/xla/service/dump.cc:485] HloModule dump enabled with path prefix: , suffix: before_optimizations
2023-03-13 20:34:24.053945: I tensorflow/compiler/jit/xla_compilation_cache.cc:477] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
XLA execution: 0.5849842810421251 seconds
10000*10000 :
2023-03-13 20:36:19.998069: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX_VNNI FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-03-13 20:36:20.072443: I tensorflow/core/util/port.cc:104] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2023-03-13 20:36:20.074511: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2023-03-13 20:36:20.074522: I tensorflow/compiler/xla/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
2023-03-13 20:36:20.427811: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory
2023-03-13 20:36:20.427845: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory
2023-03-13 20:36:20.427849: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
2023-03-13 20:36:20.758529: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory
2023-03-13 20:36:20.758546: W tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:265] failed call to cuInit: UNKNOWN ERROR (303)
2023-03-13 20:36:20.758554: I tensorflow/compiler/xla/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (nisl-System-Product-Name): /proc/driver/nvidia/version does not exist
2023-03-13 20:36:20.758746: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX_VNNI FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
NoXLA execution: 89.6282888110145 seconds
2023-03-13 20:37:50.752523: I tensorflow/compiler/xla/service/service.cc:173] XLA service 0x37fd3a0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2023-03-13 20:37:50.752548: I tensorflow/compiler/xla/service/service.cc:181] StreamExecutor device (0): Host, Default Version
2023-03-13 20:37:50.754435: I tensorflow/compiler/xla/service/dump.cc:485] HloModule dump enabled with path prefix: , suffix: before_optimizations
2023-03-13 20:37:50.777762: I tensorflow/compiler/jit/xla_compilation_cache.cc:477] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
XLA execution: 72.45748333900701 seconds
Why not use @tf.function(jit_compile=True) on small data to get higher runtime efficiency?