Why Deep Convolutional Neural Network GAN, trained using my step sequence, doesn’t performs good as in the GFG DC-GAN Tutorial example? Even tho my code is similar in logic and resembles same to the one from GFG DC-GAN.
As the question above sounds, it seems like I’m missing a very major thing and there is certainly some very big blunder. But the problem is that despite days of manual bugging of these few lines of code, I’ve not been able to successfully track down the issue with my code. I need some urgent help regarding the issue as soon as possible and would appreciate any help. Thank You.
Note: We both are using same default dataset: tf.keras.datasets.fashion_mnist.load_data()[0]
My Notebook: Google Colab
GFG Version : Deep Convolutional GAN with Keras - GeeksforGeeks
- Results with my code vs the GFG Version of the Code.

(GFG Version of the Code, after 1st Epoch and 128 batch size)

(My Version of the Code, after training 1000 batch size and 60 epochs in total)
As you can see, my model fails severely to converge to the desired result and for some reason, I notice mode collapse or something which doesn’t lets my model converge to the desired results.
I’m posting the code of my training sequence as well as a bit of explaination of what it does in the following section:
def training_sequence(batch_size=1000, epochs=60):
for epoch in range(epochs):
print("Epoch: " + str(epoch + 1) + " of " + str(epochs))
#Training Discriminator:
GAN.layers[0].trainable = False
GAN.layers[1].trainable = True
#1 for real samples and 0 for fake samples
fake_generated_examples = generator(generate_random_sequence(size = int(batch_size / 2)))
zeros = tf.zeros((int(batch_size / 2), 1, 1, 1))
#train discriminator
discriminator.fit(fake_generated_examples, zeros)
ones = tf.ones((int(batch_size / 2), 1, 1, 1))
real_examples = x_train[int(batch_size / 2)*(epoch) : int(batch_size / 2)*(epoch + 1)].reshape(int(int(batch_size / 2)*(epoch + 1) - int(batch_size / 2)*(epoch)), 28, 28, 1)
#train discriminator
discriminator.fit(real_examples, ones)
#Training Generator
GAN.layers[0].trainable = True
GAN.layers[1].trainable = False
#train generator
GAN.fit(generate_random_sequence(size = int(batch_size / 2)), ones)
There are two models (I’ll post the summary just bit after their introduction) -
- Discriminator: Takes in an input of
(28, 28, 1)and outputs :[[[[1]]]]for real samples (the ones from dataset) and[[[[0]]]]for fake ones (which are generated from Generators. - GAN: It is a Sequence of Generator and Discriminator model. It takes in a random value of
(1, 100)and returns the output from discriminator.
generate_random_sequences(size) is just a function to generate a number of random 100 numbers of size rows and (1,100) columns which are fed into generator.
int(batch_size / 2)*(epoch) used in the code is just used to select first batch_size instances from the dataset in each epoch loop and keep selecting next batch size and so on, so there is no repetition of selection of a data from dataset during each epoch and they remain unique.
Here’s my model architecture:
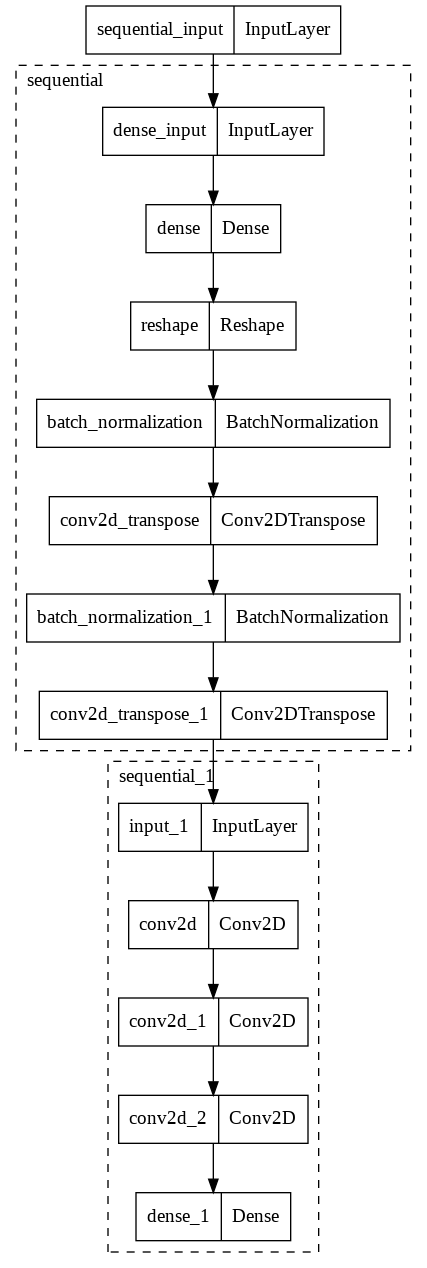
(My Model Architecture)
As you all can see it is very similar to the one from GFG.
So, as apparently seen from the whole mess above, it certainly seems I’ve missed something which others haven’t. I don’t know the issue yet and I really need help of someone experienced to guide me with my endeavors further. Thank you everyone.