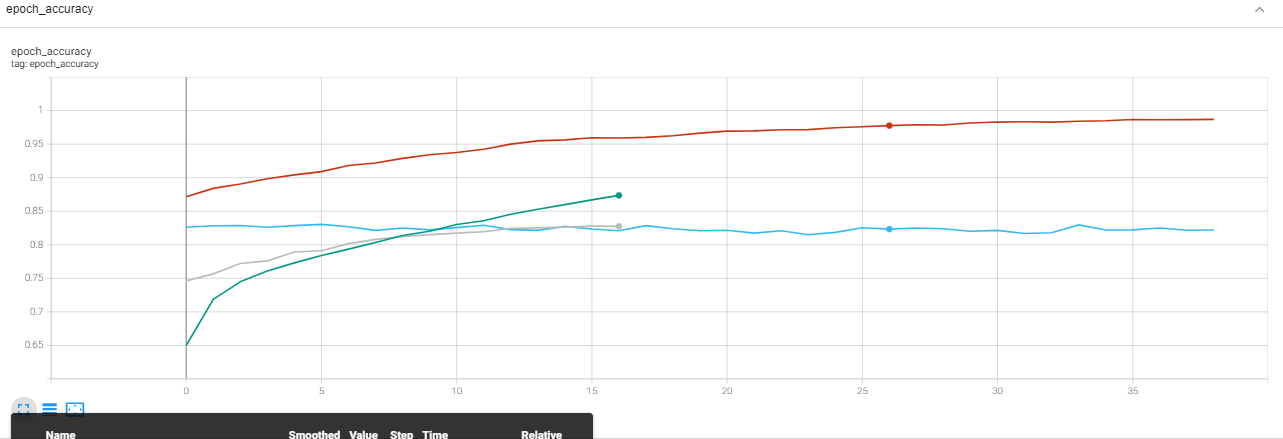
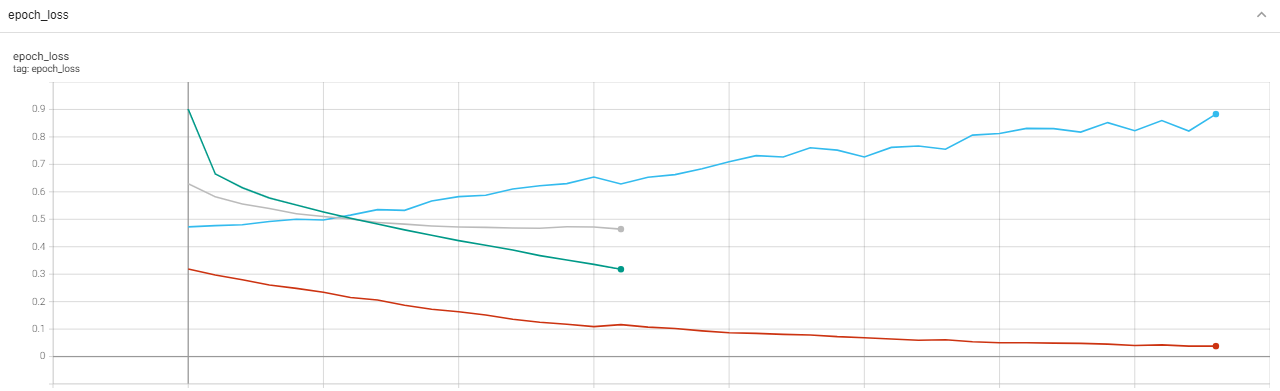
I trained a resnet50 network with 17 epochs for image classification. After the train, I ran the same command with 35 epochs. In this step, I used the checkpoint of the previous step. As you can see in the pictures below, in the second stage of training, the evaluation loss is not reduced.
Hi @Elahimanesh
Welcome to the TensorFlow Forum!
The training loss fluctuation depends on the how model architecture s defined and how the model was saved and restored for retraining. Could you please share minimal reproducible code to replicate and to understand the issue better. Thank you.
Hi @Renu_Patel
Thank you for your response to my question on the TensorFlow Forum.
It has been quite some time since I asked the initial question. The codes for that project are no longer available, and the project itself has changed significantly. I appreciate your response and willingness to help.
Thank you for your understanding.