import tensorflow.compat.v1 as tf
import tensorflow.compat.v1.keras as K
!pip install tf_slim
tf.disable_v2_behavior()
#tf.enable_eager_execution()
import numpy as np
import pandas as pd
print(tf.__version__)
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import random as rd
import numpy as np
from tensorflow.python.ops import control_flow_ops
def apply_with_random_selector(x, func, num_cases):
"""Computes func(x, sel), with sel sampled from [0...num_cases-1].
Args:
x: input Tensor.
func: Python function to apply.
num_cases: Python int32, number of cases to sample sel from.
Returns:
The result of func(x, sel), where func receives the value of the
selector as a python integer, but sel is sampled dynamically.
"""
sel = tf.random_uniform([], maxval=num_cases, dtype=tf.int32)
# Pass the real x only to one of the func calls.
return control_flow_ops.merge([
func(control_flow_ops.switch(x, tf.equal(sel, case))[1], case)
for case in range(num_cases)])[0]
def distort_color(image, color_ordering=0, fast_mode=True, scope=None):
"""Distort the color of a Tensor image.
Each color distortion is non-commutative and thus ordering of the color ops
matters. Ideally we would randomly permute the ordering of the color ops.
Rather then adding that level of complication, we select a distinct ordering
of color ops for each preprocessing thread.
Args:
image: 3-D Tensor containing single image in [0, 1].
color_ordering: Python int, a type of distortion (valid values: 0-3).
fast_mode: Avoids slower ops (random_hue and random_contrast)
scope: Optional scope for name_scope.
Returns:
3-D Tensor color-distorted image on range [0, 1]
Raises:
ValueError: if color_ordering not in [0, 3]
"""
with tf.name_scope(scope, 'distort_color', [image]):
if fast_mode:
if color_ordering == 0:
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
else:
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
else:
if color_ordering == 0:
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
elif color_ordering == 1:
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
elif color_ordering == 2:
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
elif color_ordering == 3:
image = tf.image.random_hue(image, max_delta=0.2)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.image.random_brightness(image, max_delta=32. / 255.)
else:
raise ValueError('color_ordering must be in [0, 3]')
# The random_* ops do not necessarily clamp.
return tf.clip_by_value(image, 0.0, 1.0)
def distorted_bounding_box_crop(image,
bbox,
min_object_covered=0.5,
aspect_ratio_range=(0.75, 1.33),
area_range=(0.5, 1.0),
max_attempts=100,
scope=None):
"""Generates cropped_image using a one of the bboxes randomly distorted.
See `tf.image.sample_distorted_bounding_box` for more documentation.
Args:
image: 3-D Tensor of image (it will be converted to floats in [0, 1]).
bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
where each coordinate is [0, 1) and the coordinates are arranged
as [ymin, xmin, ymax, xmax]. If num_boxes is 0 then it would use the whole
image.
min_object_covered: An optional `float`. Defaults to `0.1`. The cropped
area of the image must contain at least this fraction of any bounding box
supplied.
aspect_ratio_range: An optional list of `floats`. The cropped area of the
image must have an aspect ratio = width / height within this range.
area_range: An optional list of `floats`. The cropped area of the image
must contain a fraction of the supplied image within in this range.
max_attempts: An optional `int`. Number of attempts at generating a cropped
region of the image of the specified constraints. After `max_attempts`
failures, return the entire image.
scope: Optional scope for name_scope.
Returns:
A tuple, a 3-D Tensor cropped_image and the distorted bbox
"""
with tf.name_scope(scope, 'distorted_bounding_box_crop', [image, bbox]):
# Each bounding box has shape [1, num_boxes, box coords] and
# the coordinates are ordered [ymin, xmin, ymax, xmax].
# A large fraction of image datasets contain a human-annotated bounding
# box delineating the region of the image containing the object of interest.
# We choose to create a new bounding box for the object which is a randomly
# distorted version of the human-annotated bounding box that obeys an
# allowed range of aspect ratios, sizes and overlap with the human-annotated
# bounding box. If no box is supplied, then we assume the bounding box is
# the entire image.
sample_distorted_bounding_box = tf.image.sample_distorted_bounding_box(
tf.shape(image),
bounding_boxes=bbox,
min_object_covered=min_object_covered,
aspect_ratio_range=aspect_ratio_range,
area_range=area_range,
max_attempts=max_attempts,
use_image_if_no_bounding_boxes=True)
bbox_begin, bbox_size, distort_bbox = sample_distorted_bounding_box
# Crop the image to the specified bounding box.
cropped_image = tf.slice(image, bbox_begin, bbox_size)
return cropped_image, distort_bbox
def preprocess_for_train(image, height, width, bbox,
fast_mode=True,
crop = True,
scope=None,
add_image_summaries=True):
"""Distort one image for training a network.
Distorting images provides a useful technique for augmenting the data
set during training in order to make the network invariant to aspects
of the image that do not effect the label.
Additionally it would create image_summaries to display the different
transformations applied to the image.
Args:
image: 3-D Tensor of image. If dtype is tf.float32 then the range should be
[0, 1], otherwise it would converted to tf.float32 assuming that the range
is [0, MAX], where MAX is largest positive representable number for
int(8/16/32) data type (see `tf.image.convert_image_dtype` for details).
height: integer
width: integer
bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
where each coordinate is [0, 1) and the coordinates are arranged
as [ymin, xmin, ymax, xmax].
fast_mode: Optional boolean, if True avoids slower transformations (i.e.
bi-cubic resizing, random_hue or random_contrast).
scope: Optional scope for name_scope.
add_image_summaries: Enable image summaries.
Returns:
3-D float Tensor of distorted image used for training with range [-1, 1].
"""
with tf.name_scope(scope, 'distort_image', [image, height, width, bbox]):
if bbox is None:
bbox = tf.constant([0.0, 0.0, 1.0, 1.0],
dtype=tf.float32,
shape=[1, 1, 4])
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# Each bounding box has shape [1, num_boxes, box coords] and
# the coordinates are ordered [ymin, xmin, ymax, xmax].
image_with_box = tf.image.draw_bounding_boxes(tf.expand_dims(image, 0),
bbox)
if add_image_summaries:
tf.summary.image('image_with_bounding_boxes', image_with_box)
#
if crop:
distorted_image, distorted_bbox = distorted_bounding_box_crop(image, bbox)
distorted_image.set_shape([None, None, 3])
image_with_distorted_box = tf.image.draw_bounding_boxes(
tf.expand_dims(image, 0), distorted_bbox)
# distorted_image = tf.image.central_crop(image, central_fraction=rd.uniform(0.7,1))
else:
distorted_image = image
# Restore the shape since the dynamic slice based upon the bbox_size loses
# the third dimension.
if add_image_summaries:
tf.summary.image('images_with_distorted_bounding_box',
image_with_distorted_box)
# This resizing operation may distort the images because the aspect
# ratio is not respected. We select a resize method in a round robin
# fashion based on the thread number.
# Note that ResizeMethod contains 4 enumerated resizing methods.
# We select only 1 case for fast_mode bilinear.
num_resize_cases = 1 if fast_mode else 4
distorted_image = apply_with_random_selector(
distorted_image,
lambda x, method: tf.image.resize_images(x, [height, width], method),
num_cases=num_resize_cases)
if add_image_summaries:
tf.summary.image('cropped_resized_image',
tf.expand_dims(distorted_image, 0))
# Randomly flip the image horizontally.
distorted_image = tf.image.random_flip_left_right(distorted_image)
distorted_image = tf.image.random_flip_up_down(distorted_image)
# Randomly distort the colors. There are 4 ways to do it.
distorted_image = apply_with_random_selector(
distorted_image,
lambda x, ordering: distort_color(x, ordering, fast_mode),
num_cases=4)
if add_image_summaries:
tf.summary.image('final_distorted_image',
tf.expand_dims(distorted_image, 0))
# distorted_image_final = tf.subtract(distorted_image, 0.5)
# distorted_image_final = tf.multiply(distorted_image_final, 2.0)
return distorted_image
def preprocess_for_eval(image, height, width,
central_fraction=0.875, scope=None):
"""Prepare one image for evaluation.
If height and width are specified it would output an image with that size by
applying resize_bilinear.
If central_fraction is specified it would crop the central fraction of the
input image.
Args:
image: 3-D Tensor of image. If dtype is tf.float32 then the range should be
[0, 1], otherwise it would converted to tf.float32 assuming that the range
is [0, MAX], where MAX is largest positive representable number for
int(8/16/32) data type (see `tf.image.convert_image_dtype` for details).
height: integer
width: integer
central_fraction: Optional Float, fraction of the image to crop.
scope: Optional scope for name_scope.
Returns:
3-D float Tensor of prepared image.
"""
with tf.name_scope(scope, 'eval_image', [image, height, width]):
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# Crop the central region of the image with an area containing 87.5% of
# the original image.
if central_fraction:
image = tf.image.central_crop(image, central_fraction=central_fraction)
if height and width:
# Resize the image to the specified height and width.
image = tf.expand_dims(image, 0)
image = tf.image.resize_bilinear(image, [height, width],
align_corners=False)
image = tf.squeeze(image, [0])
# image = tf.subtract(image, 0.5)
# image = tf.multiply(image, 2.0)
return image
def preprocess_image(image, height, width,
is_training=False,
bbox=None,
crop = False,
fast_mode=True,
add_image_summaries=True):
"""Pre-process one image for training or evaluation.
Args:
image: 3-D Tensor [height, width, channels] with the image. If dtype is
tf.float32 then the range should be [0, 1], otherwise it would converted
to tf.float32 assuming that the range is [0, MAX], where MAX is largest
positive representable number for int(8/16/32) data type (see
`tf.image.convert_image_dtype` for details).
height: integer, image expected height.
width: integer, image expected width.
is_training: Boolean. If true it would transform an image for train,
otherwise it would transform it for evaluation.
bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
where each coordinate is [0, 1) and the coordinates are arranged as
[ymin, xmin, ymax, xmax].
fast_mode: Optional boolean, if True avoids slower transformations.
add_image_summaries: Enable image summaries.
Returns:
3-D float Tensor containing an appropriately scaled image
Raises:
ValueError: if user does not provide bounding box
"""
if is_training:
return preprocess_for_train(image, height, width, bbox, fast_mode,crop = crop,
add_image_summaries=add_image_summaries)
else:
return preprocess_for_eval(image, height, width,central_fraction=1.0)
# from mittens import Mittens
# from mittens import GloVe
import numpy as np
import csv
from sklearn.feature_extraction.text import CountVectorizer
#from preprocessing import inception_preprocessing
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def get_captions(tfrecord):
record_iterator = tf.python_io.tf_record_iterator(tfrecord)
annotations = []
for string_record in record_iterator:
example = tf.train.Example()
example.ParseFromString(string_record)
annotations.append(example.features.feature['labels'].bytes_list.value[0])
return annotations
def preProBuildWordVocab(sentence_iterator, word_count_threshold=20): # function from Andre Karpathy's NeuralTalk
vectorizer = CountVectorizer(lowercase=False, dtype=np.float64, ngram_range=(1, 1),
stop_words=('Lesions', 'START'))
X = vectorizer.fit_transform(sentence_iterator)
Xc = (X.T * X)
vocab = vectorizer.get_feature_names()
vocab2 = [w.encode() for w in vocab]
return Xc.todense(), vocab, vocab2, np.diagonal(Xc.todense())
def parse_fn_train(example):
"Parse TFExample records"
example_fmt = {
'height': tf.io.FixedLenFeature([], tf.int64),
'width': tf.io.FixedLenFeature([], tf.int64),
'image_raw': tf.io.FixedLenFeature((), tf.string),
"labels": tf.io.FixedLenFeature((), tf.string, "")
}
parsed = tf.io.parse_single_example(example, example_fmt)
height = tf.cast(parsed['height'], tf.int32)
width = tf.cast(parsed['width'], tf.int32)
image = tf.io.decode_raw(parsed['image_raw'], tf.uint8)
image = tf.reshape(image, (height, width, 3))
return image, parsed["labels"]
def parse_fn_test(example):
"Parse TFExample records"
example_fmt = {
'height': tf.io.FixedLenFeature([], tf.int64),
'width': tf.io.FixedLenFeature([], tf.int64),
'image_raw': tf.io.FixedLenFeature((), tf.string),
"labels": tf.io.FixedLenFeature((), tf.string, "")
}
parsed = tf.io.parse_single_example(example, example_fmt)
height = tf.cast(parsed['height'], tf.int32)
width = tf.cast(parsed['width'], tf.int32)
image = tf.io.decode_raw(parsed['image_raw'], tf.uint8)
image = tf.reshape(image, (height, width, 3))
return image, parsed["labels"]
def read_and_decode(dataset, batch_size, is_training, data_size):
if is_training:
dataset = dataset.shuffle(buffer_size=data_size, reshuffle_each_iteration=True)
dataset = dataset.prefetch(buffer_size=data_size // batch_size)
dataset = dataset.map(map_func=parse_fn_train, num_parallel_calls=tf.data.experimental.AUTOTUNE,
)
dataset = dataset.batch(batch_size, drop_remainder=False)
else:
dataset = dataset.prefetch(buffer_size=data_size // batch_size)
dataset = dataset.map(map_func=parse_fn_train, num_parallel_calls=tf.data.experimental.AUTOTUNE,
)
dataset = dataset.batch(batch_size, drop_remainder=False)
return dataset
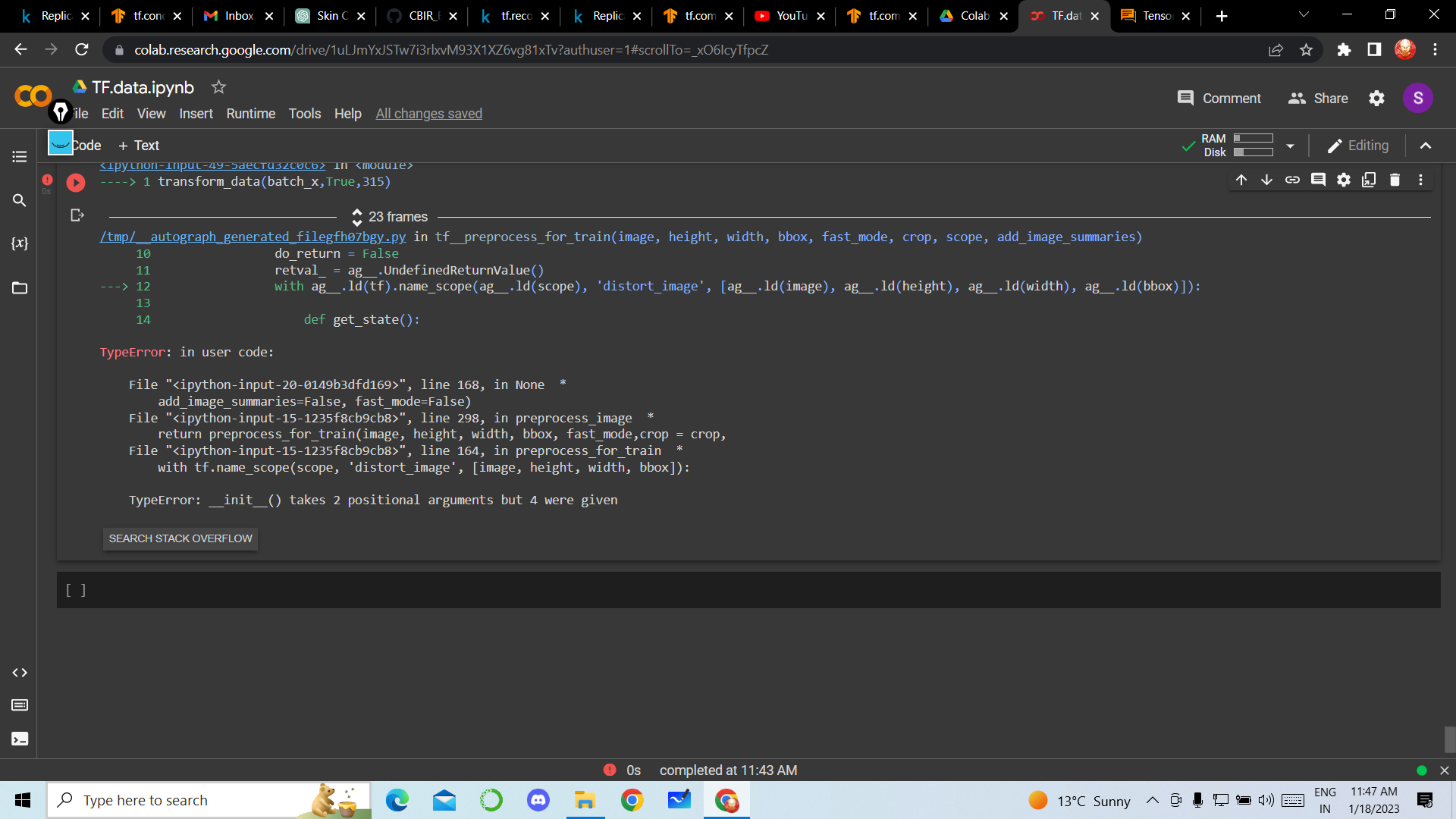
def transform_data(img, is_training, dim):
image_dense = tf.map_fn(
lambda x: preprocess_image(x, dim, dim, is_training=is_training,
add_image_summaries=False, fast_mode=False), img,
dtype=tf.float32)
image_dense = tf.to_float(tf.image.convert_image_dtype(image_dense, tf.uint8))
return
# # from mittens import Mittens
# # from mittens import GloVe
# import tensorflow.compat.v1 as tf
# import tensorflow.compat.v1.keras as K
# tf.disable_v2_behavior()
import numpy as np
import csv
from sklearn.feature_extraction.text import CountVectorizer
# #from preprocessing import inception_preprocessing
def _bytes_feature(value):
"""Returns a bytes_list from a string / byte."""
if isinstance(value, type(tf.constant(0))): # if value ist tensor
value = value.numpy() # get value of tensor
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _float_feature(value):
"""Returns a floast_list from a float / double."""
return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))
def _int64_feature(value):
"""Returns an int64_list from a bool / enum / int / uint."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def serialize_array(array):
array = tf.io.serialize_tensor(array)
return array
def get_captions(tfrecord):
record_iterator = tf.compat.v1.io.tf_record_iterator(tfrecord)
annotations = []
for string_record in record_iterator:
example = tf.train.Example()
example.ParseFromString(string_record)
annotations.append(example.features.feature['labels'].bytes_list.value[0])
return annotations
def preProBuildWordVocab(sentence_iterator, word_count_threshold=20): # function from Andre Karpathy's NeuralTalk
vectorizer = CountVectorizer(lowercase=False, dtype=np.float64, ngram_range=(1, 1),
stop_words=('Lesions', 'START'))
X = vectorizer.fit_transform(sentence_iterator)
Xc = (X.T * X)
vocab = vectorizer.get_feature_names()
vocab2 = [w.encode() for w in vocab]
return Xc.todense(), vocab, vocab2, np.diagonal(Xc.todense())
# def parse_fn_train(example):
# "Parse TFExample records"
# example_fmt = {
# 'height': tf.FixedLenFeature([], tf.int64),
# 'width': tf.FixedLenFeature([], tf.int64),
# 'image_raw': tf.FixedLenFeature((), tf.string),
# "labels": tf.FixedLenFeature((), tf.string, "")
# }
# parsed = tf.parse_single_example(example, example_fmt)
# height = tf.cast(parsed['height'], tf.int32)
# width = tf.cast(parsed['width'], tf.int32)
# image = tf.decode_raw(parsed['image_raw'], tf.uint8)
# image = tf.reshape(image, (height, width, 3))
# return image, parsed["labels"]
def parse_fn_train(example):
"Parse TFExample records"
example_fmt = {
'height': tf.io.FixedLenFeature([], tf.int64),
'width': tf.io.FixedLenFeature([], tf.int64),
'image_raw': tf.io.FixedLenFeature((), tf.string),
"labels": tf.io.FixedLenFeature((), tf.string, "")
}
parsed = tf.io.parse_single_example(example, example_fmt)
height = tf.cast(parsed['height'], tf.int32)
width = tf.cast(parsed['width'], tf.int32)
image = tf.io.decode_raw(parsed['image_raw'], tf.uint8)
image = tf.reshape(image, (height, width, 3))
# height = parsed['height']
# width = parsed['width']
# #depth = parsed['depth']
label = parsed['labels']
# raw_image = parsed['image_raw']
return image,label
# def parse_fn_test(example):
# "Parse TFExample records"
# example_fmt = {
# 'height': tf.FixedLenFeature([], tf.int64),
# 'width': tf.FixedLenFeature([], tf.int64),
# 'image_raw': tf.FixedLenFeature((), tf.string),
# "labels": tf.FixedLenFeature((), tf.string, "")
# }
# parsed = tf.parse_single_example(example, example_fmt)
# height = tf.cast(parsed['height'], tf.int32)
# width = tf.cast(parsed['width'], tf.int32)
# image = tf.decode_raw(parsed['image_raw'], tf.uint8)
# image = tf.reshape(image, (height, width, 3))
# return image, parsed["labels"]
def parse_fn_test(example):
"Parse TFExample records"
example_fmt = {
'height': tf.io.FixedLenFeature([], tf.int64),
'width': tf.io.FixedLenFeature([], tf.int64),
'image_raw': tf.io.FixedLenFeature((), tf.string),
"labels": tf.io.FixedLenFeature((), tf.string, "")
}
parsed = tf.io.parse_single_example(example, example_fmt)
height = tf.cast(parsed['height'], tf.int32)
width = tf.cast(parsed['width'], tf.int32)
image = tf.io.decode_raw(parsed['image_raw'], tf.uint8)
image = tf.reshape(image, (height, width, 3))
# height = parsed['height']
# width = parsed['width']
# #depth = parsed['depth']
label = parsed['labels']
# raw_image = parsed['image_raw']
return image,label
def read_and_decode(dataset, batch_size, is_training, data_size):
if is_training:
dataset = dataset.shuffle(buffer_size=data_size, reshuffle_each_iteration=True)
dataset = dataset.prefetch(buffer_size=data_size // batch_size)
dataset = dataset.map(map_func=parse_fn_train, num_parallel_calls=tf.data.experimental.AUTOTUNE,
)
dataset = dataset.batch(batch_size, drop_remainder=False)
else:
dataset = dataset.prefetch(buffer_size=data_size // batch_size)
dataset = dataset.map(map_func=parse_fn_train, num_parallel_calls=tf.data.experimental.AUTOTUNE,
)
dataset = dataset.batch(batch_size, drop_remainder=False)
return dataset
def transform_data(img, is_training, dim):
image_dense = tf.map_fn(
lambda x: preprocess_image(x, dim, dim, is_training=is_training,
add_image_summaries=False, fast_mode=False), img,
dtype=tf.float32)
image_dense = tf.to_float(tf.image.convert_image_dtype(image_dense, tf.uint8))
return image_dense
path ="/content/drive/MyDrive/Fold_1_T3/train_full_norm.tfrecords"
data=dataset_train = tf.data.TFRecordDataset(path, num_parallel_reads=4)
data=read_and_decode(data,32,True,8012)
train_val_iterator = tf.compat.v1.data.Iterator.from_structure(tf.compat.v1.data.get_output_types(data), tf.compat.v1.data.get_output_shapes(data))
batch_x, batch_y = train_val_iterator.get_next()
train_iterator = train_val_iterator.make_initializer(data)
transform_data(batch_x,True,315)
**
**