Hello Everyone! I’m planning to buy the M1 Max 32 core gpu MacBook Pro for some Machine Learning (using TensorFlow) like computer vision and some NLP tasks. Is it worth it? Does the TensorFlow use the M1 gpu or the neural engine to accelerate training? I can’t decide what to do? To be transparent I have all Apple devices like the M1 iPad Pro, iPhone 13 Pro, Apple Watch, etc., So I try so hard not to buy other brands with Nvidia gpu for now, because I like the tight integration of Apple eco-system and the M1 Max performance and efficiency. Also, currently I use Google Colab on my 2017 MacBook Air. Desktop is not an option because I travel a lot. Kindly please help me to decide. Thank You All!
3 Likes
In theory, porting should do this carefree (it’s python), but if Apple was that good at using Keras / TensorFlow, if it was a go-to platform, it would know. I have great doubts, the base M1 equivalent to an RTX 2070, with the performance of a GPU, from AMD, I find that it is less desirable at once. If it is an urgent purchase: either, if you can wait, consider an Nvidia desktop and GPU
Apple have released a TensorFlow plugin (linked below) that allows you to directly use their Metal API to run TensorFlow models on their GPUs. This plugin supports their new M1 chips. While I’ve not tried it on the new M1 Max the general GPU architecture is the same as before and the Metal API remains the same, so in theory this should work. The plugin is being released by Apple themselves so it seems likely that they will make sure that is up to date.
Note that the TensorFlow plugin interface needs TF 2.5 or later.
2 Likes
yes, I used it in my friend’s M1 MacBook Air. But few packages was not supported.
You can see some benchmarks here (credits to the repository author). The experiments I ran so far lead me to think that M1 Max is comparable to my GeForce GTX TITAN X in terms of fp32 deep learning speed performance (of course, M1 Max consumes way less power…). Recent Nvidia cards benefit greatly from fp16 training speedup.
2 Likes
I have been using the M1 Max 14” for some CNN testing and calibrating and it is very good. For most tasks about 25% better than the Colab Pro P100 instance. I don’t know what the NVIDIA cards can do but it looks to me that you would have to spend quite a lot to get substantially better performance.
The tensorflow-metal plugin at 0.2.0 works quite well although I suspect that still want to clean up quite a bit more. Most packages that I have tried work quite well but some are harder to install (such as CatBoost). Using conda to install them has generally worked well for me.
If you are happy with the Apple ecosystem then I think you are likely to be happy with an M1 Max machine.
1 Like
Can you give some more details, what exactly part of the M1 Max are mostly beneficial for TensorFlow? Is it the GPU or the Neural Engine? Since i am kind of running low on budget, so i thought of go with less GPU cores should only the number of neural core matters.
You can’t use the neural engine for training using TensorFlow. I’ve order the 16 core GPU model and that will be fine for me. Because I planned to build a separate workstation with Nvidia GPU and right now I use cloud services to train my models. So if have a tight budget 16 core GPU model will do just fine.
Thank you for your clarification. According to metal doc Tensorflow Plugin - Metal - Apple Developer, only a single GPU can be utilised by metal backend currently. So a larger number of GPU cores on M1 Max doesn’t provide much advantage for TensorFlow, should I do not use distributed training with multiple containers. Am I right? And is it even possible to use multiple metal pods with minikube on M1 Max?
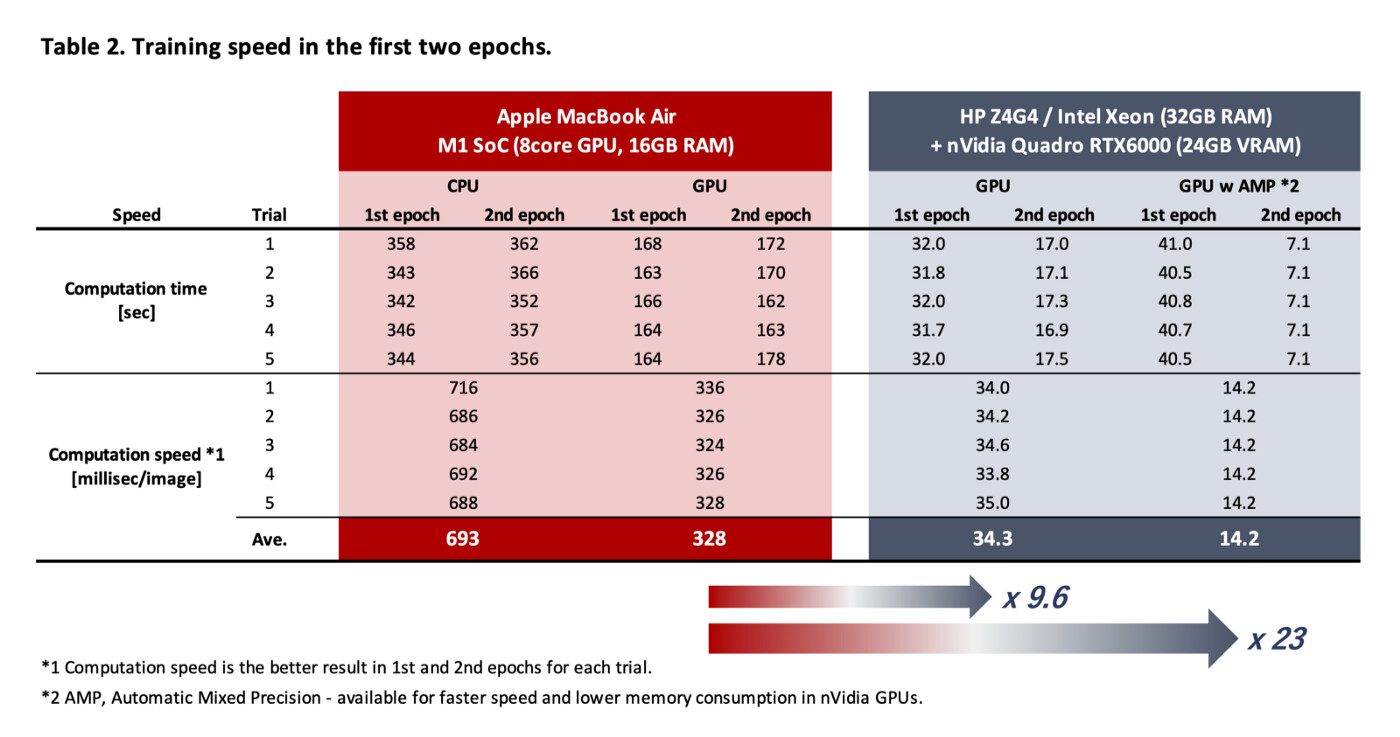
Hi. I tried a training task of image segmentation using TensorFlow/Keras on GPUs, Apple M1 and nVidia Quadro RTX6000.
RTX6000 is 20-times faster than M1(not Max or Pro) SoC, when Automatic Mixed Precision is enabled in RTX…
I posted the benchmark in Medium with an estimation of M1 Max (I don’t have an M1 Max machine).
1 Like
I don’t have any Nvidia GPUs to compare to so my only comparison is Colab Pro and CPUs.
The M1 Max with 32 GPU cores generally performs about 4 times faster than the M1 in my testing - just as you would expect. It is sometimes a closer to 5x in some cases which I am guessing is related to unified memory but that is a guess and I am far from an expert in hardware optimisation for ML.
For very small image sizes and very small batch sizes, the M1 Max GPU (and M1) don’t really offer much (but the CPU performs well in those cases). When the batch and image sizes get larger the M1 Max starts to kick in.
When compared to Colab Pro (P100 GPU), the M1 Max was 1-1.25x the speed of Colab Pro. For me that works well because it means that I can train models that take a longer time without worrying about timeouts. However, from other posts it sounds like an RTX6000 could make everything significantly faster. However, it is not practical for me to get a separate system with an RTX6000 (as the card itself costs more than my entire M1 Max computer).
I guess my summary is that the M1 Max seems like a reasonable medium level system - significantly faster than similarly priced systems but not in the same league as higher cost setups.
1 Like
Interesting thread. A question to the TensorFlow developers: now that Apple is diving deep into GPU performance, is there any plan to have a native TF support for Metal API (or at least to Apple silicon acceleration)?
any plan to have a native TF support for Metal API (or at least to Apple silicon acceleration)
I don’t know if the TFRT runtime will still give, at some point, other kind of HW integratoin paths in TF other then pluggable devices that what is currently supported with the tensorflow-metal wheel:
/cc @penporn
1 Like
I agree with you. Depending on situations, I will choose M1 Max/Pro.
In fact, when I train a regression model, MacBook Air M1 has enough power with reasonable training time.
 Thanks for sharing
Thanks for sharing
Here’re an interesting table - M1 8core GPU 16GB RAM on a Macbook Air vs RTX6000 24GB RAM with Xeon 32GB RAM - from @takashi 's post:
@Bhack Thank you for the quick answer and for tagging me!
https://tensorflow-prod.ospodiscourse.com/t/accelerating-tensorflow-using-apple-m1-max/5282/21
@Doug We consider the TensorFlow-Metal plug-in a native support. Future device integrations to the current TensorFlow stack will be in the form of PluggableDevice plug-ins that work with the official TensorFlow packages.
2 Likes
Will this still valid also when TFRT/MLIR will be more integrated in TF?
As one year ago we had this position:
1 Like
Many thanks @penporn for clarifying! I meant PluggableDevices were not native because - to the best of my understanding - they are not automatically updated once the “main” TF is updated, and their source code is not open, right? But, in any case, it’s already pretty good to be able to accelerate on Apple gear.
Hi Yingding,
Tensorflow Metal plugin utilizes all the core of M1 Max GPU. It appears as a single Device in TF which gets utilized fully to accelerate the training. Distributed training is used for the multi-host scenario. Where different Hosts (with single or multi-gpu) are connected through different network topologies.
Many thanks @kulin_seth for your clarification, I will max out the number of GPU cores on M1 Max and also the RAM probably for TensorFlow training.
Regarding Federated ML, which might be unrelated to this thread top, it appears to me Apple M1 chip doesn’t support JAX with GPU yet and probably also not for FedJAX. Currently, there is also an issue with TensorFlow Federated on M1.
Can TensorFlow team share some timeline regarding the support of TensorFlow Federated on M1 Max/Pro?
Is there any way to do Federated ML effectively on M1 Max/Pro with GPU cores? Many thanks in advance.
1 Like