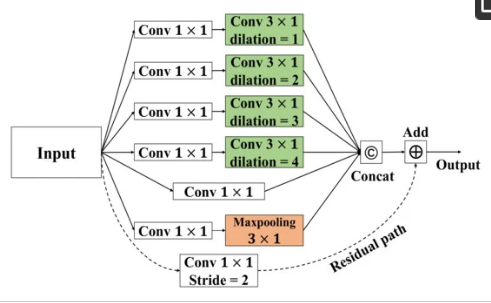
I am thinking of how would it be if I can create asynchronous forward function in sub-class of nn.Module . When I came across architecture in attached image, I felt that it would be faster if we could train pass through each branch parallelly.
Another scenario I have come across is when input is of shape (B, C ,V ,T) , where :
B: batch_sz , C: node_features , V : num_nodes , T : time_stamps
So, there is a graph for each time-stamp corresponding to each instance in the batch. Now there is a module which calculates Adj_matrix of a graph based on its node_features… It would be compute intensive if we club (B,C,V,T)->(BxT, C,V) , and then treat (B*T) as new batch , where T~=250 , B=32…
Is there some work-around that we can evaluate adj_mat efficiently… This problem is not only limited to calculation of adj_mat through my custom module, but rather to use any graph layer from PyG, we need to club B,T
I’m not talking about training on multiple GPU, but making calls asynchronously rather than sequentially.
Please answer both the question , thanks in advance