Hello everyone,
probably a very noob question, I’m just started in this new magic worl of AI and ML. I’ve run every tutorial project I could find, i develop my own Dog or Cat model by transfering from MobileNet.
I’m now struggling with the classification of documents.
I have 50 companies that sends us invoices and I want to train a model in order to recognize which company sent us the invoice automatically. The document structure is basically the same (some minor differences in the structure of a table) the main difference lies in the logo of the company of course.
The images are very large, so what I’m trying right now is this:
(using Tensorflow.js if it metters)
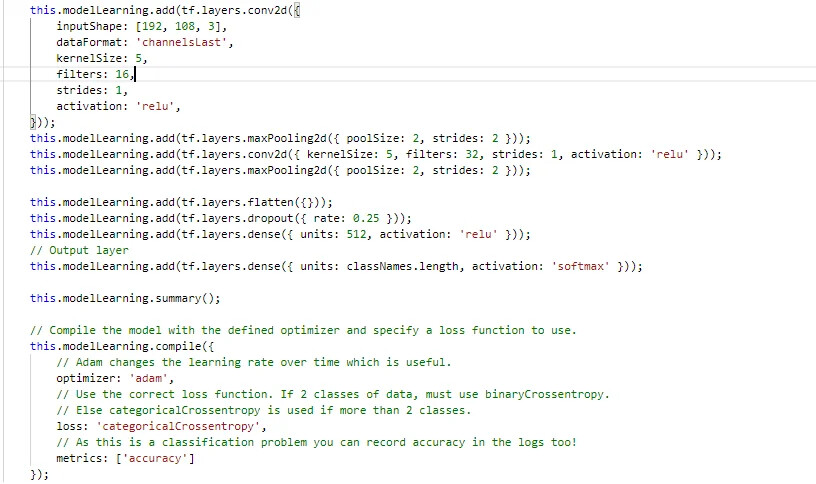
This the network i thought it could work.
I process every image in this way:
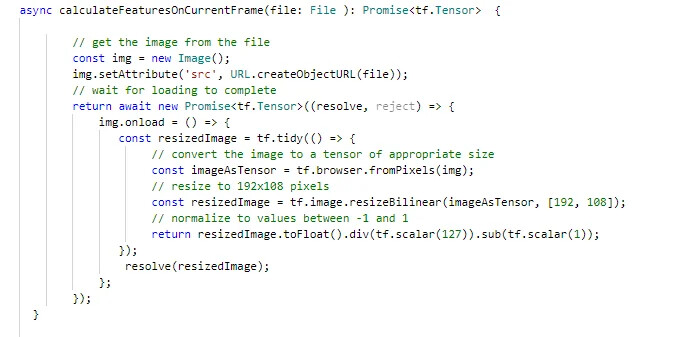
Then i try to train the model with this code:
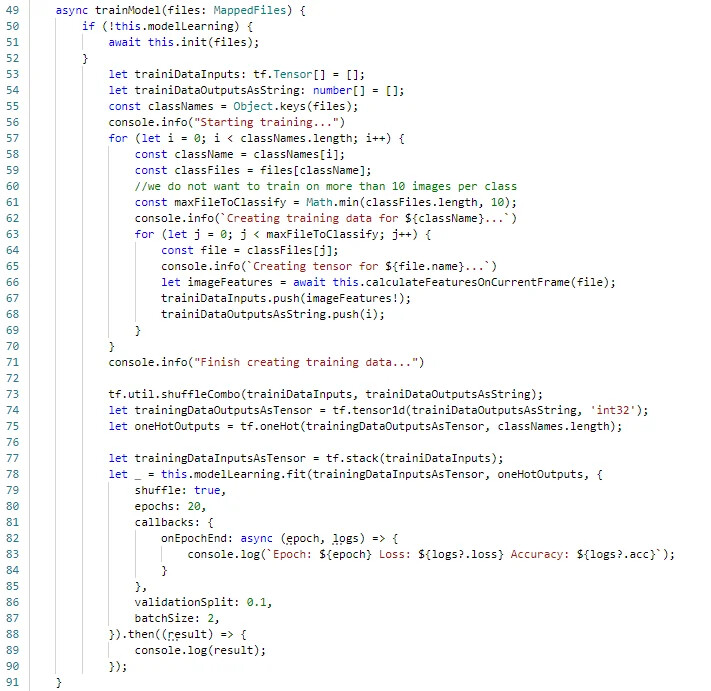
But at this point the log tells me that it will not reach 0.4 as accuracy.
Can you point me in the right direction?