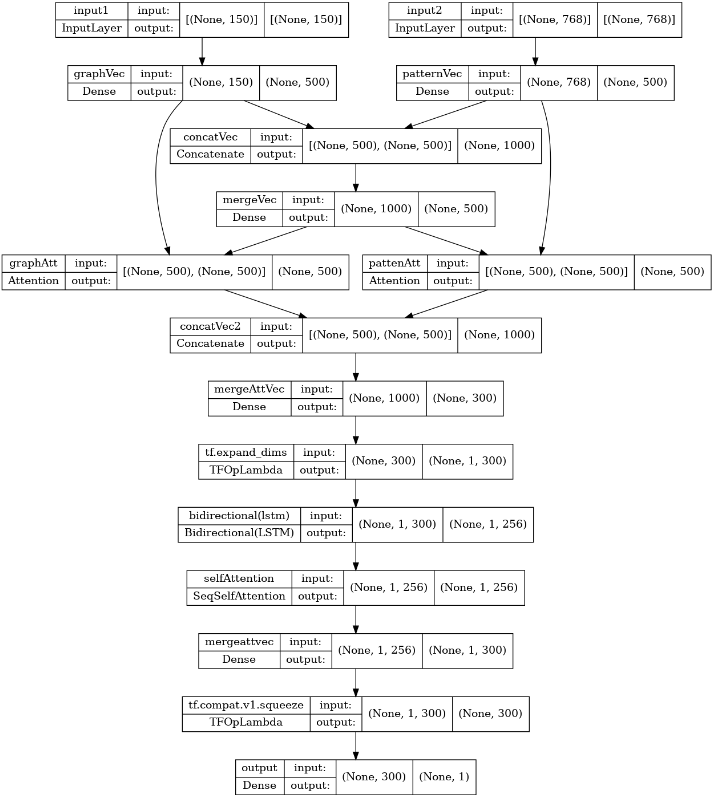
In recent research, I tried the following model to fuse the two features, and then train and classify them. In theory, this method of distributed self-attention mechanism is used to perform two kinds of features separately, then connect them in dimension, and finally input them to the model for training and classification, also known as the cross-attention mechanism in the field of feature fusion.
However, the classification results obtained by our team through the training of the following models are very, very poor. Originally, the two types of features were simply classified by random forest, and the classification accuracy was about 92%. The training results of the models in the above pictures were only less than 50% training accuracy.
I am very confused about this result. I also ask the professionals of TensorFlow and the friends in the community to help me take a look and analyze whether there is a problem in the model network, which leads to the lack of learned feature information?
thank you very much! Looking forward to professional insights and replies~
I don’t know why I can’t post pictures today, please check the model link below:
https://i.postimg.cc/SRfyT8sc/cross-attention.png
{kind=link}