Both training and validation datasets are cached to disk.
In my understanding, after the first epoch (once the cache is filled) the following elements should reside in memory:
1000 elements due to shuffling of training data
1 batch, 20 elements of training data currently used
1 batch, 20 elements of training data prefetched
1 batch, 20 elements of validation data prefetched
In size this is about 1060 elements, a total of 1.75 GB.
I am sure there must be some additional overhead, but the key thing is the memory footprint should level off around some value and stay there throughout the entire training (if I am right).
Running a training on a Google Colab T4 GPU
after the first epoch, the system memory use is about 6.9 GB
during the 4th epoch it is 12.0 GB
the runtime crashes a few seconds later, due to running out of memory
I did some testing, and turned out the shuffle() transformation being the culprit.
First I thought this is a memory leak, but no, simply shuffle just has a horrible memory overhead.
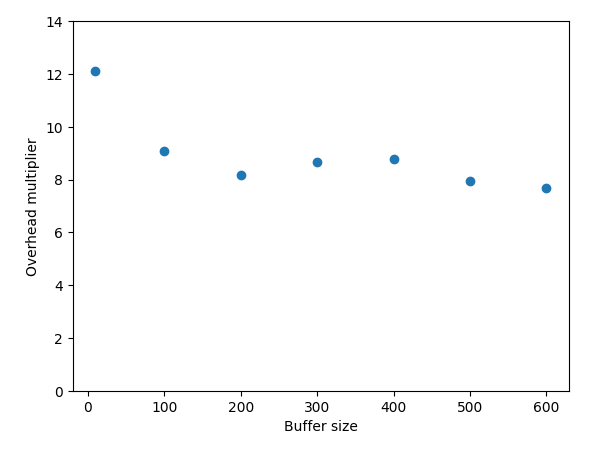
I did a quick benchmark, took 1000 samples of 1,69 MB each and tested different shuffle buffer sizes to see the memory/buffer_size ratio which turned out to be pretty constant:
So, as a general rule of thumb, if you do a shuffle, plan to have 8.4 (!) times your buffer_size memory available.
I guess it might be worth mentioning this in the documentation.
Wow, that was a terrible answer you got on GitHub.
But this part is new to me .prefetch(buffer_size=tf.data.experimental.AUTOTUNE) - does this have any effect on the very weird effect you are seeing where the memory requirement increased after the first epoch (which it shouldn’t - the pipeline should perform fairly similarly in each epoch).
Actually the linked ticket is not mine, just added it as another example of the same phenomenon.
And if you choose a shuffle buffer size small enough the memory allocation eventually settles around a fixed value (that’s what I did in my benchmark) – not necessarily after the first epoch but within a few, I guess that’s the nature of heavy memory management done in the background.
I have no bad experience with prefetch(), it does what it says: preloads the next unit (usually a batch) to be passed to the GPU. It has no adverse impact on memory footprint, but I choose one batch in my test.
About your questioned expression (which can be simplified as .prefetch(tf.data.AUTOTUNE)). There’s no much information available on what prefetch autotune actually does, but this SO article might be helpful. Nevertheless, it is the generally advised setting.
Ah, that’s nice. I thought the minimally reproducible example was a bit too minimal in the ticket. But I wasn’t gonna call you out on it
I don’t think I’ve ever written a model that consumed more than one batch per training step but I guess it could happen and that there might be some other compute advantages I haven’t considered from using more than 1 for prefetch.