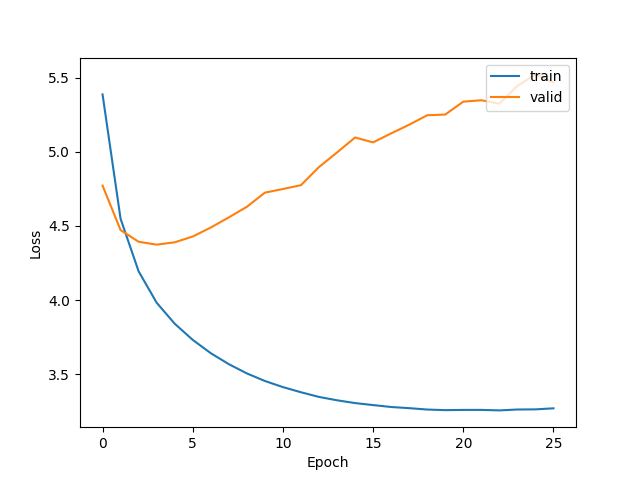
I think I have an overfitting problem … my goal is image captioning Datasets : training 8000 … testing 1000 this my model for 50 epochs
def define_model(vocab_size, max_length):
inputs1 = Input(shape=(1120,))
f1 = Dropout(0.5)(inputs1)
f2 = Dense(256, activation='relu')(f1)
inputs2 = Input(shape=(max_length,))
s1 = Embedding(vocab_size, 256, mask_zero=True)(inputs2)
s4 = GRU(512)(s1)
decoder1 = Concatenate()([f2, s4])
f3 = Dropout(0.5)(decoder1)
decoder2 = Dense(256, activation='relu')(f3)
outputs = Dense(vocab_size, activation='softmax')(decoder2)
model = Model(inputs=[inputs1, inputs2], outputs=outputs)
opt =tf.keras.optimizers.Adam(lr=4e-4)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
I tried also to use BatchNormalization and learning rate with 0.0001 but the performance become poor