Hi,
I noticed that the Model.fit with verbose=2 seems to print loss & accuracy at different times for the training vs validation datasets. Upon reading the source code, it seems like these values were computed before the one epoch sweep for the training dataset, whereas for the validation dataset, they were computed after the sweep is completed. Let’s say we do a simple training like this:
model_1H_history = model_1H.fit(train_features,
train_L_onehot,
epochs=10, batch_size=32,
validation_data=(test_features, test_L_onehot),
verbose=2)
and get the following output:
Epoch 1/10
6827/6827 - 12s - loss: 1.1037 - accuracy: 0.6752 - val_loss: 0.5488 - val_accuracy: 0.8702
Epoch 2/10
6827/6827 - 12s - loss: 0.4071 - accuracy: 0.9048 - val_loss: 0.3205 - val_accuracy: 0.9245
Epoch 3/10
6827/6827 - 12s - loss: 0.2743 - accuracy: 0.9319 - val_loss: 0.2425 - val_accuracy: 0.9385
...
Epoch 8/10
6827/6827 - 13s - loss: 0.1209 - accuracy: 0.9740 - val_loss: 0.1172 - val_accuracy: 0.9739
Epoch 9/10
6827/6827 - 12s - loss: 0.1089 - accuracy: 0.9770 - val_loss: 0.1058 - val_accuracy: 0.9770
Epoch 10/10
6827/6827 - 12s - loss: 0.0996 - accuracy: 0.9785 - val_loss: 0.0970 - val_accuracy: 0.9792
If we plot “as is” the history of the values of the “loss”, placing the loss and val_loss values on the same epoch numbers, then the output looks like this:
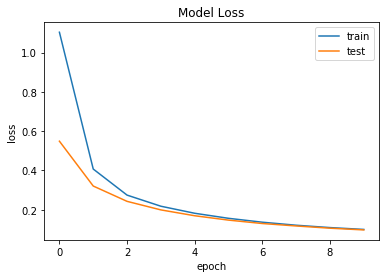
which does not look reasonable: Why the test (validation) dataset yields lower loss function for the same epoch?
However, if we shift the epoch values associated with val_loss by one, then the plot will look like this:
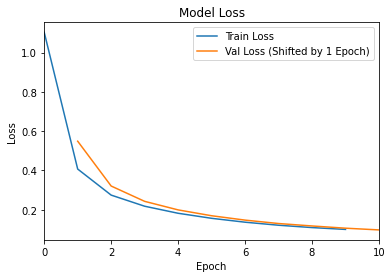
This looks much more sensible.
My question is this: Is the apparent epoch difference above intentional?* I.e. that for the loss and accuracy (against training dataset) were computed before the training sweep, whereas val_loss and val_accuracy after the sweep?
Wirawan