def get_dataset(batch_size: int, df = None, fold=0):
"""
Get TensorFlow BatchDataset objects for train and validation data.
Args:
train_split (float): Percentage of the dataset to use for training.
batch_size (int): Batch size for the dataset.
Returns:
train_dataset (tf.data.Dataset): BatchDataset object for the training data.
validation_dataset (tf.data.Dataset): BatchDataset object for the validation data.
"""
train_paths, validation_paths, train_labels, validation_labels = _get_from_csv(df=df, label_column="class_name", fold=fold)
train_labels_le, validation_labels_le = _encode_labels(train_labels=train_labels, validation_labels=validation_labels)
print(train_labels_le)
class_weights = _get_classweights(train_labels_le)
data_augmentation = apply_augmentations()
train_ds = tf.data.Dataset.from_tensor_slices((train_paths, train_labels_le))
validation_ds = tf.data.Dataset.from_tensor_slices(
(validation_paths, validation_labels_le)
)
# Train pipeline
pipeline_train = (
train_ds.shuffle(buffer_size=batch_size * 10)
.map(_preprocess_image, num_parallel_calls=_AUTO)
.batch(batch_size)
.map(lambda x, y: (data_augmentation(x), y), num_parallel_calls=_AUTO)
.prefetch(_AUTO)
)
# Validation Pipeline
pipeline_validation = (
validation_ds.map(_preprocess_image, num_parallel_calls=_AUTO)
.batch(batch_size)
.prefetch(_AUTO)
)
return class_weights, pipeline_train, pipeline_validation
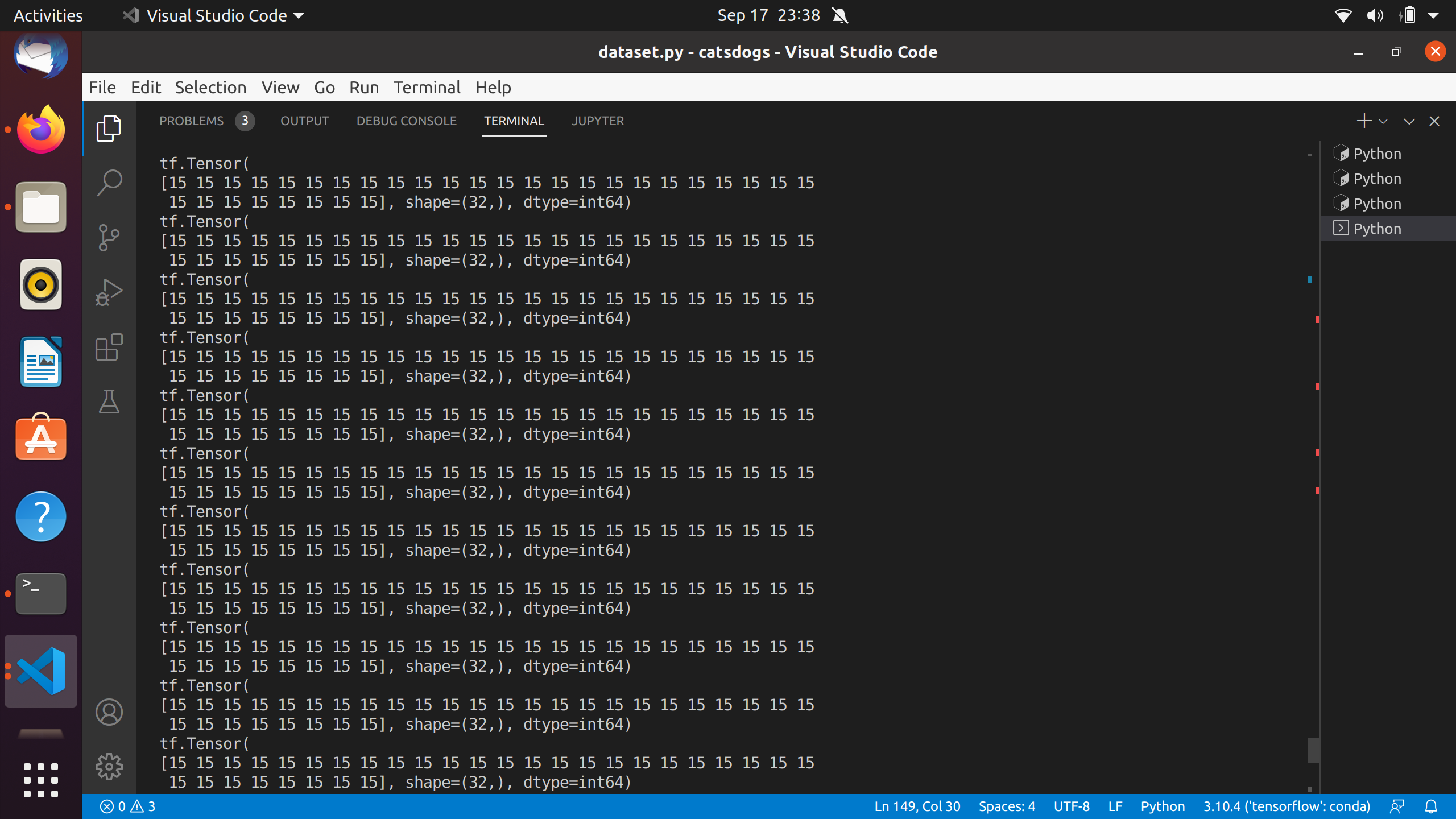
I have provided the dataset generator function and the screenshot of the outputs of it.
Try preparing the dataset in the following order: tf.data.Dataset.from_tensor_slices(…) → use .map() to transform the data if needed → use .shuffle() → use .batch() → use .prefetch()
Thanks, I solved it, just replaced the shuffle buffer size to the size of the original dataset