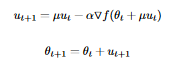Greetings to everyone, I have been studying first-order optimization algorithms and spotted diferences between those mentioned in their original papers and the implemented ones. Specifically, I have questions about Nesterov’s Accelerated Gradient (NAG), Adadelta, and AdamW.
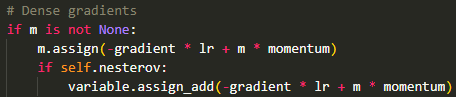
NAG: Could someone explain how these two update rules are the same? Additionally, where is the implemented accelerated gradient?
Adadelta: Why is there a default learning rate of 0.001 when the original implementation has no learning rate? If one were to derive the original, the learning rate would be set to 1. Does Adadelta perform better with this learning rate? In my experience, it does not.
AdamW: Where is implemented the decoupled weight decay?
Thank you in advance. I would also appreciate any constructive criticism regarding the structure or content of my post.
Hi @Xristos_Krallis .
To help a bit - Implementation of optimizers or layers in Tensorflow happen to be slightly different from original paper (it is the same for Pytorch).
As per optimizers, one can look into the code of each optimizer. You’ll see Tensorflow team cites the research paper it is based on.
Thank you.
Thank you, @tagoma, for your fast response. While I understand that there may be slight differences between the implemented versions and the original paper, I can accept that for AdamW and Adadelta. However, NAG seems to deviate significantly from the original paper, as the calculation of the gradient does not take into consideration the term utut. Your response has prompted another question. I initially thought that the optimizers were located in /keras/optimizers/etc, and my questions are based on these implementations. Is it possible that I am looking in the wrong direction? Thank you in advance.