I’m working on my first non-trivial tensorflow project (predicting moves-to-mate for chess endgames) and I’ve run across some odd behavior in the training stage. In multiple models I have trained on my data, the network looks like it has forgotten everything and restarts from scratch. How do I avoid this?
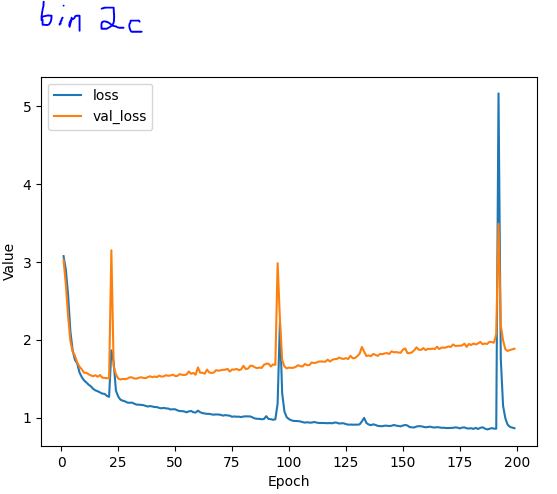
Training data is 40,000 samples, Adam optimizer, batch size 2000
I know my model is way over-parameterized at the moment, but the smaller models I tried weren’t accurate enough
.
def create_model_eg_bin2c(my_learning_rate):
“”“Create and compile a deep neural net.”""
# This is a first try to get a simple model that works
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(
filters=64, kernel_size=(3,3), input_shape=(8,8,15), strides=(1, 1), padding=‘same’))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Conv2D(
filters=32, kernel_size=(3,3), strides=(1, 1), padding=‘same’))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(units=33))
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=my_learning_rate),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[‘accuracy’])
return model