Hi, I have a weired problem with training a PPO agent.
I have taken the PPO example from git and gave it my own environment. In that environment the agent learns to act based on a time series. Training works as intended, but as I decided to use RNN/LSTM I encountered a problem with using a single environment for trajectory collection:
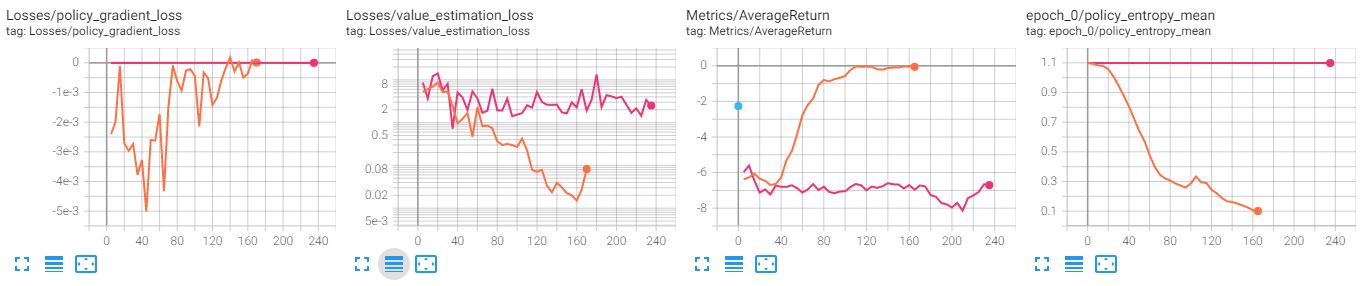
The policy network is not learning at all while the value network changes, but doesn’t really improve, too. This happens ONLY with num_parallel_environments=1.
Here a comparison of 2 vs 1 parallel environments (identical implementation):
this is how i define the env(s)
tf_env = TFPyEnvironment(
ParallelPyEnvironment(
[lambda: env_load_fn(train_df)] * num_parallel_environments))
actor_net = actor_distribution_rnn_network.ActorDistributionRnnNetwork(
tf_env.observation_spec(),
tf_env.action_spec(),
input_fc_layer_params=actor_fc_layers,
lstm_size=lstm_size,
output_fc_layer_params=None,)
value_net = value_rnn_network.ValueRnnNetwork(
tf_env.observation_spec(),
input_fc_layer_params=value_fc_layers,
output_fc_layer_params=None)
Has anyone an idea?