What goes on under the hood of Vision Transformers is seldom talked about. We mostly acknowledge the attention formulae and stand in awe looking at how good Vision Transformers work.
In our(w/ @ariG23498) work we inspect various phenomena of a Vision Transformer and provide arguments for what we observe. We share insights from various relevant works done in this area and provide concise implementations that are compatible with Keras models. Alongside investigating the representations learned by various Vision Transformer model families (original, DeiT, DINO), we also provide their implementations in Keras populated with their respective pre-trained parameters.
In order to facilitate future research, we release code, models, a tutorial, interactive demos (via Hugging Face Spaces), visuals here:
The code repository houses all of our experiments and observations. If you’ve got a new analysis experiment you’d like us to include please contribute or reach out to us 
We hope our work turns out to be a useful resource for practitioners working with Vision Transformers.
Below are some visualizations that we were able to reproduce:
The famous DINO style heatmap video:

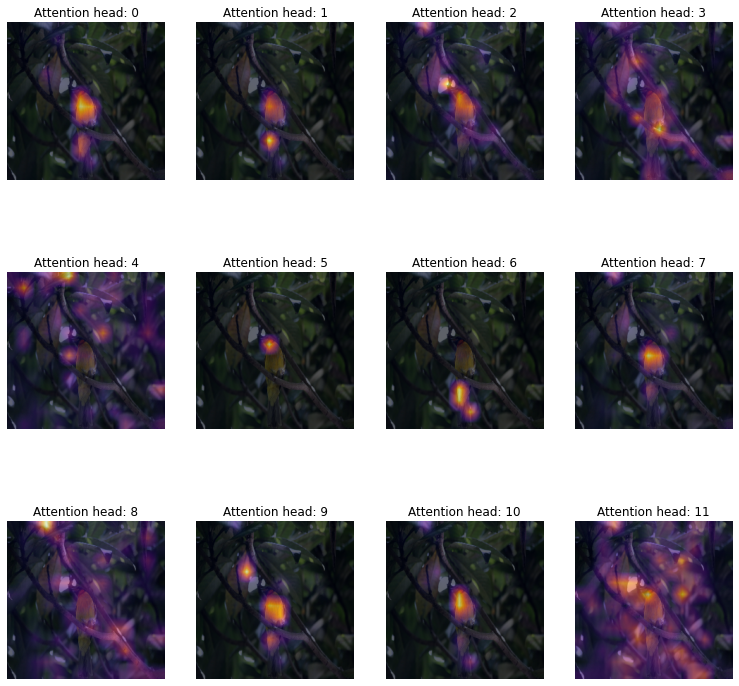
Heatmaps from individual attention heads from the last Transformer block:
Attention rollout:

Visualization of the different learned projection filters:

We are thankful to @fchollet for providing feedback on the tutorial, Jarvis Labs, and the GDE program for providing us credit support that allowed our experiments.
Thanks to @Ritwik_Raha for helping us with this amazing infographic on mean attention distance:
