Gato is a single, large, transformer sequence model; a multi-modal, multi-task, multi-embodiment generalist policy
Post: A Generalist Agent (DeepMind.com)
Research: https://storage.googleapis.com/deepmind-media/A%20Generalist%20Agent/Generalist%20Agent.pdf
Inspired by progress in large-scale language modelling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato.
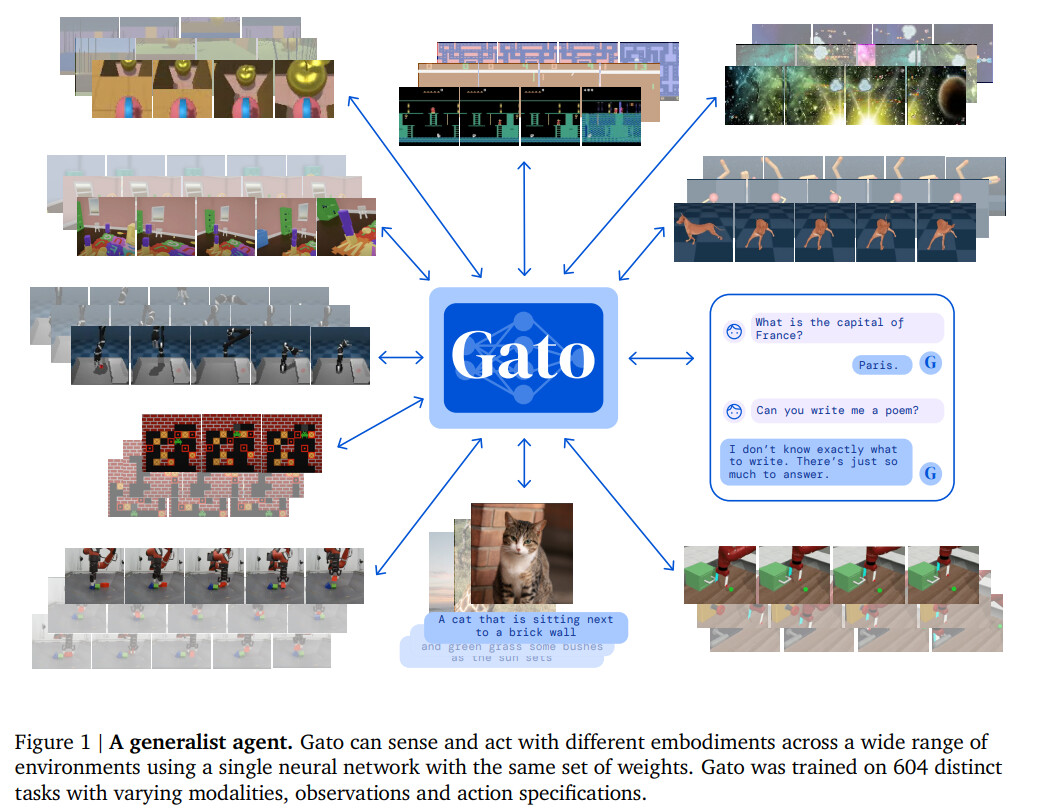
In this paper, we describe the current iteration of a general-purpose agent which we call Gato,
instantiated as a single, large, transformer sequence model. With a single set of weights, Gato can
engage in dialogue, caption images, stack blocks with a real robot arm, outperform humans at playing Atari games, navigate in simulated 3D environments, follow instructions, and more.
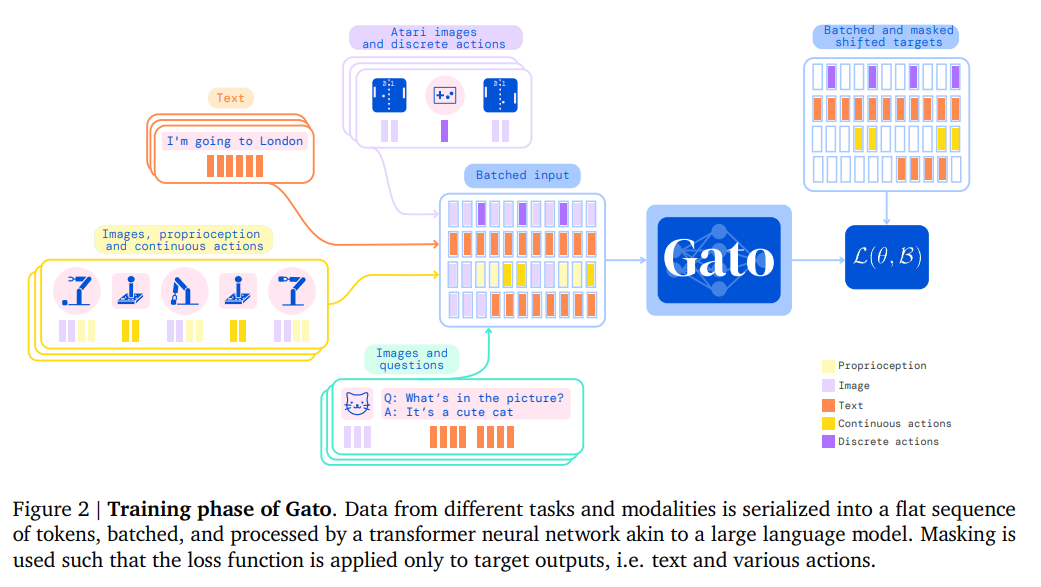
Gato is trained on a large number of datasets comprising agent experience in both simulated and real-world environments, in addition to a variety of natural language and image datasets. The number of tasks, where the performance of the pretrained Gato model is above a percentage of expert score, grouped by domain, is shown here.
Related work
The most closely related architectures to that of Gato are Decision Transformers (Chen et al., 2021b; Reid et al., 2022; Zheng et al., 2022) and Trajectory Transformer (Janner et al., 2021), which showed the usefulness of highly generic LLM-like architectures for a variety of control problems. Gato also uses an LLM-like architecture for control, but with design differences chosen to support multi-modality, multi-embodiment, large scale and general purpose deployment. Perceiver IO (Jaegle et al., 2021) uses a transformer-derived architecture specialized to handle very long sequences, to model any modality as a sequence of bytes. This and similar architectures could be used to expand the range of modalities supported by future generalist models.
Gato was inspired by works such as GPT-3 (Brown et al., 2020) and Gopher (Rae et al., 2021),
pushing the limits of generalist language models; and more recently the Flamingo (Alayrac et al., 2022) generalist visual language model. Chowdhery et al. (2022) developed the 540B parameter
Pathways Language Model (PalM) explicitly as a generalist few-shot learner for hundreds of text tasks.
Post: A Generalist Agent (DeepMind.com)
Research: https://storage.googleapis.com/deepmind-media/A%20Generalist%20Agent/Generalist%20Agent.pdf