- New research from Google Research/Columbia University published in NeurIPS 2021.
- Convolution-free Video-Audio-Text Transformer (VATT) “takes raw signals as inputs and extracts multimodal representations that are rich enough to benefit a variety of downstream tasks.”
- Tasks include: image classification, video action recognition, audio event classification, and zero-shot text-to-video retrieval.
- Self-supervised multimodal learning strategy (pre-training requires minimal labeling).
arXiv: VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
TensorFlow code: https://github.com/google-research/google-research/tree/master/vatt
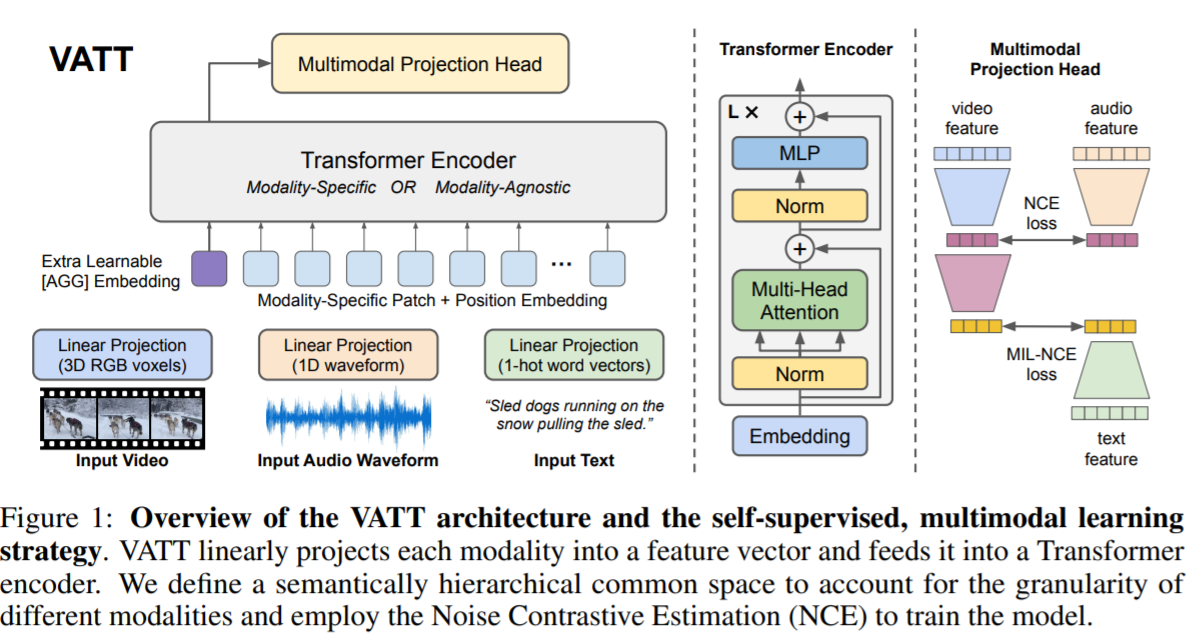
We present a framework for learning multimodal representations from unlabeled data using convolution-free Transformer architectures. Specifically, our Video-Audio-Text Transformer (VATT) takes raw signals as inputs and extracts multimodal representations that are rich enough to benefit a variety of downstream tasks. We train VATT end-to-end from scratch using multimodal contrastive losses and evaluate its performance by the downstream tasks of video action recognition, audio event classification, image classification, and text-to-video retrieval. Furthermore, we study a modality-agnostic, single-backbone Transformer by sharing weights among the three modalities. We show that the convolution-free VATT outperforms state-of-the-art ConvNet-based architectures in the downstream tasks. Especially, VATT’s vision Transformer achieves the top-1 accuracy of 82.1% on Kinetics-400, 83.6% on Kinetics-600, 72.7% on Kinetics-700, and 41.1% on Moments in Time, new records while avoiding supervised pre-training. Transferring to image classification leads to 78.7% top-1 accuracy on ImageNet compared to 64.7% by training the same Transformer from scratch, showing the generalizability of our model despite the domain gap between videos and images. VATT’s audio Transformer also sets a new record on waveform-based audio event recognition by achieving the mAP of 39.4% on AudioSet without any supervised pre-training…
… we study self-supervised, multimodal pre-training of three Transformers [88], which take as input the raw RGB frames of internet videos, audio waveforms, and text transcripts of the speech audio, respectively. We call the video, audio, text Transformers VATT… VATT borrows the exact architecture from BERT [23] and ViT [25] except the layer of tokenization and linear projection reserved for each modality separately. This design shares the same spirit as ViT that we make the minimal changes to the architecture so that the learned model can transfer its weights to various frameworks and tasks. Furthermore, the self-supervised, multimodal learning strategy resonates the spirit of BERT and GPT that the pre-training requires minimal human curated labels. We evaluate the pre-trained Transformers on a variety of downstream tasks: image classification, video action recognition, audio event classification, and zero-shot text-to-video retrieval…
In this paper, we present a self-supervised multimodal representation learning framework based on Transformers. Our study suggests that Transformers are effective for learning semantic video/audio/text representations — even if one model is shared across modalities — and multimodal self-supervised pre-training is promising for reducing their dependency on large-scale labeled data. We show that DropToken can significantly reduce the pre-training complexity with video and audio modalities and have minor impact on the models’ generalization. We report new records of results on video action recognition and audio event classification and competitive performance on image classification and video retrieval…
arXiv: VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
TensorFlow code: https://github.com/google-research/google-research/tree/master/vatt