Hello Everyone.
I am currently working on a problem that requires segmenting a video lecture transcript based on the topics present within the video. My dataset consists of sentence wise labels where 1 indicates the beginning of a new segment(ie. topic) and 0 indicates the same segment. Thus the problem can be framed as a Binary Classification problem where the model takes a sentence as input and makes a binary prediction on it . However, due of the very nature of the problem, the dataset is highly imbalanced (90% 0s and 10% 1s). As a consequence, while training the model, I have noticed that my model becomes biased and starts making all 0s predictions.
I have tried resolving this issue through using class_weights in model.fit(). However, this hasnt been of much help. If I increase the penalty on 1s class, my model starts predicting all 1s. If I lower the value, the model again starts predicting all 0s. Does someone have any ideas as to how I should resolve this issue?
There are other oversampling and undersampling techniques(eg: SMOTE), however I dont think they are suitable in my use case since that would disrupt the continuity in the video transcript.
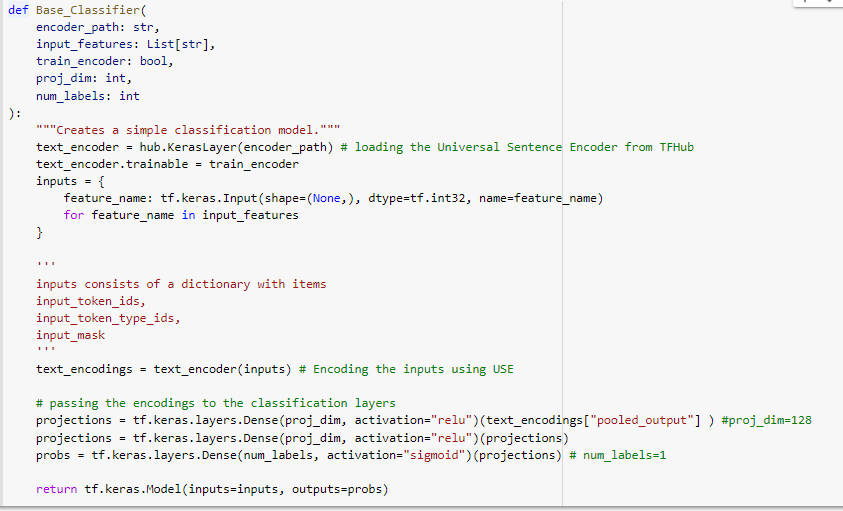
PS: I am sharing a screenshot of my model’s architecture for reference.
Basically, the model takes BERT tokenized input sentences and encodes them using the Universal Sentence Encoder. This encoding is then passed to a classification layer which finally returns a tensor of shape [BATCH_SIZE, 1]. I am using BinaryCrossentropy as a loss function.