I use this code Masked Autoencoder - Vision Transformer | Kaggle to train a network a transformer autoencoder. If I use the code under tensorflow 2.10, I obtain way better results than if I use 2.12. I don’t change the code, the data are the same, the pipeline is identical and a large number of repetitions of training shows a consistent behavior both under 2.10 and 2.12.
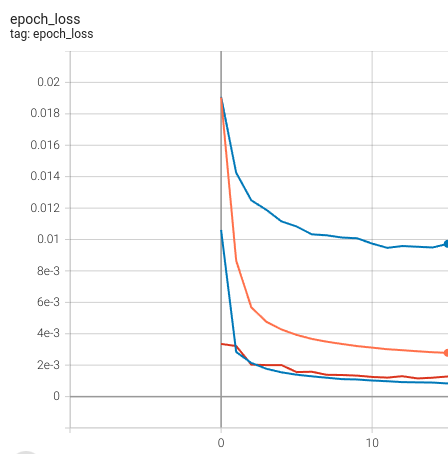
This example image shows the training and validation for 2.10 (blue and red curves, respectively) and for 2.12 (blue and orange curves on the top).
I don’t know what could generate such different results if it comes from the same code. I would appreciate if someone had a method to track down the issue.
- I saw that one big difference is the change of optimizer between 2.10 and the next versions. It is still possible to use the legacy version of adam but it did not change the results.
- I tried with 2.11, 2.12 and 2.13 using the docker image provided by the tensorflow team. All on the same computer, with the same architecture using the same GPU and the results are still significantly worse with versions newer than 2.10.
How could I track why the results are so different?
Thanks!