After the variable-length sparse feature is introduced, the feature name of the exported PB model is lost, and the input parameter name becomes args_0, args_1…
Same QA:
[1] tensorflow - tensorflow2 sparse input name missing in saved model - Stack Overflow
[2] https://github.com/tensorflow/tensorflow/issues/42018

As shown above, when the feature “tags” is FixedLenFeature, the exported PB model input structured_input_signature can normally retain all input feature names, and online TF-Serving can be used normally.
However, if the feature “tags” is VarLenFeature variable-length sparse type, the feature names in the structured_input_signature in the exported PB model are all lost, and become args_0, args_1…
And online TF-Serving, when to construct 14 features Example structure, the service reports an error:
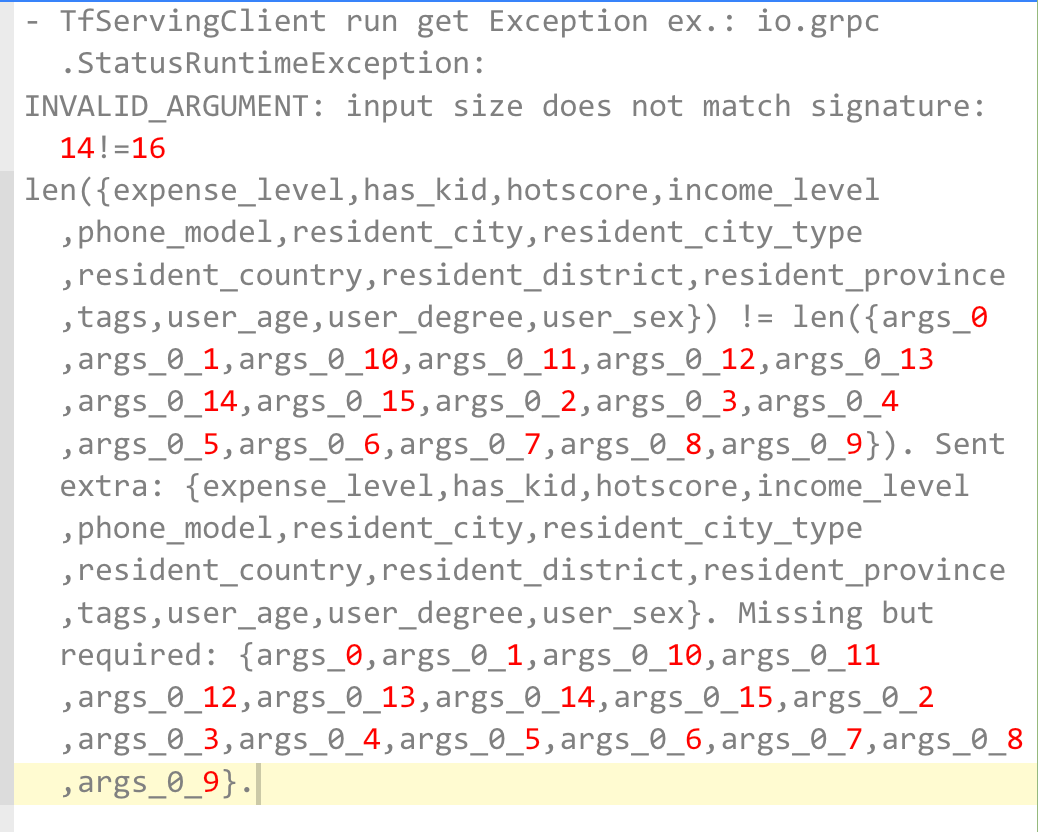
Among them, 14 is Offline model definition = 13 Fixed fixed-length features + 1 sparse feature
When the final model is exported, this 1 sparse feature will be decomposed into 3 parameters
(tags as sparse tensor, when stored in PB format, will be divided into three parameters: indices, values and shape)
Therefore, the model input in PB format is 13+3
Below is the code to save the model, both with the same error condition.
Path1
save_path = os.path.join(ckpt_dir, ‘./model’)
model.save(save_path, save_format=‘tf’)
Path2
save_path2 = os.path.join(ckpt_dir, ‘./model2’)
tf.saved_model.save(model, save_path2)
Similarly, when to define
“tags”: tf.io.RaggedFeature(tf.string, row_splits_dtype=tf.int64)
similar error
input size does not match signature: 14!=15
It seems to be a problem with the input function signature.
Do I need to rewrite the signature parameter?
Please explain the specific usage.
Thank you very much~