I did a neural network in c++ to recognize handwritten digits using the MNIST dataset without any neural network pre-existing libraries. My network has 784 inputs neuron (the pixel of the image), 100 neuron in the single hidden layer and 10 output neurons. I also have 1 bias neuron per layer. My activation function is the sigmoid function (top get ouputs between 0 and 1). My cost function is the root mean squared error. i have a learning rate 0.1 and a gradient descent momentum of 0.3.
I get an accuracy of about 90% on the MNIST training set. However on the testing set I only get a 30% accuracy. I did check the error rate during the training and I saw that it decreases for the first 120 epochs. Then it gets stuck at 0.30.
That is a plot of the cost function during all 60 000 epochs of the training :

This is also the cost function during the training but only the first 600 epochs :

And this is a plot of the cost function during the validation set (10 000 epochs) :
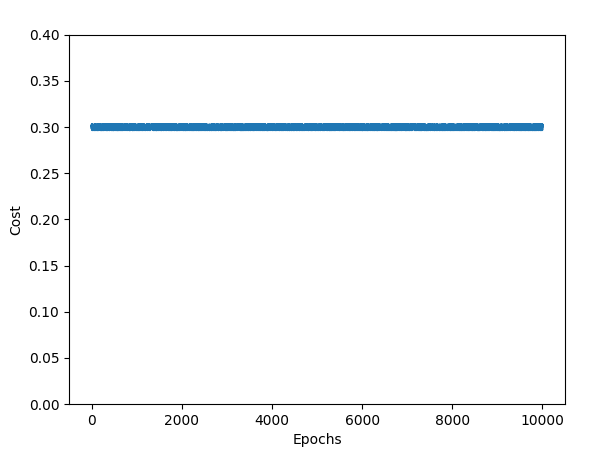
First I suspected an overfitting problem, so I tried stopping the learning right after the plateau appeared (at 120 epochs). It was worse : in the testing set, I only got 10% accuracy. I also tried dropout regularization which didn’t work, so I don’t really know if it’s an overfitting related problem.
I tried using the ReLU activation function for the hidden layers instead of the sigmoid to avoid the vanishing gradient problem without success (I got down to 10% accuracy).
Then, I tried changing the learning rate, but the plateau still appeared at 120 epochs, as I thought it would at least delay the “plateau” apparition. I also tried disabling the gradient descent momentum without any success.
I thought my cost function was stuck in a local minimum (explaining the plateau at 0.3), so I tried decreasing the learning rate as the network WAS training (starting at 0.5 and decreasing it by a fraction of number of epochs), hoping it would make the cost function “unstuck” from that local minumum but it didn’t.
I tried changing the size of the hidden layer, even adding one more, but it didn’t change anything. There is still a “plateau” and it still starts at 120 epochs.
What can I do to solve this problem ?