The SpaghettiNet-EdgeTPU model is a new Object Detection model that has been mentioned in a few different places on the Google Ai Blog and in the Tensorflow Object Detection API github.
I downloaded SpaghettiNet model, ran it on the Pixel 6 with the NNAPI delegate, and holy hell this thing is fast!
I’m not sure how to go about training a model like this , so I am looking for some guidance.
If anybody has done this before I would greatly appreciate some insight.
The blog article you linked mentions the SpaghettiNet model was trained using neural architecture search. There are a few resources around covering that topic, like this list of tools.
For a quick-and-easy first try, a commercial product like Google Cloud’s AutoML might help? Though I’m not sure if you can provide the kind of controls they talked about in the article (e.g. moving the compute budget to different parts of the network), or optimising for latency. Some of the solutions allow export to “mobile optimised” models though.
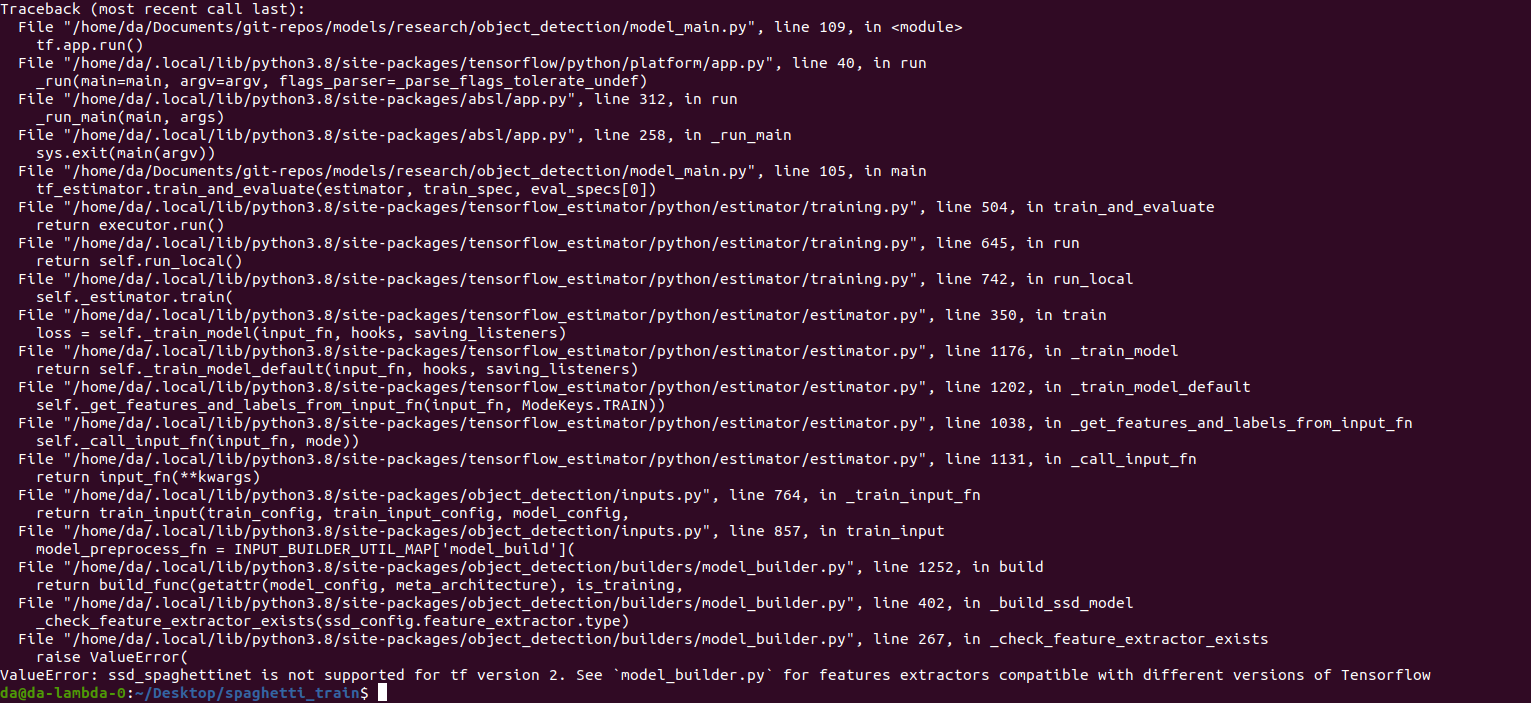
I was hoping I could just use TensorFlows Object Detection API along with this SpaghettiNet config file. I tried this using TF2 but it says that this model is not compatible with TF2. I’m now trying to use TF1… bad idea?
I want to do transfer learning for my own data. However, I just got done training this model from the pipeline.config and have a saved_model.pb file. I’m pretty sure this is just training from scratch and has no transfer learning involved(correct me if I’m wrong). It was quite annoying to get everything properly configured, but I only needed to succeed with this configuration one time.
Configuration:
Python: 3.7.0
Tensorflow: 1.15
Pycocotools: 2.0.4
Numpy: 1.18.5
Using model_main.py from the Object Detection API
I’m working on converting this to a tflite model now.
The model can be trained using the Object Detection API, as @Isaac_Padberg has demonstrated. Although the architecture was derived using AutoML, one can train it just like any other model using Tensorflow + ODAPI with some changes to the config file according to your use case. It trains from scratch.
To get it to run with TF 2.x, the feature extractor code will need to be rewritten to use TF2, but only floating point inference will work. We use TF1 because it relies on some quantization-aware training features that are not yet ported to TF2. If you would like to train without quantization, simply remove the graph_rewriter section from the pipeline.config file.
If training with quantization, the rule of thumb is to set the quantization delay parameter in the graph_rewriter config to ~10% of the total training steps (num_steps in the config). We include this delay to stabilize training but it should spend most of its time training with quantization so that it can adjust to the reduced precision.
When converting to TFLite, use mean and std values of 128 since the input is UINT8. The model is quantized until the very last operation. Here, a TFLite Detection_PostProcess custom op takes in the UINT8 model output and dequantizes it, runs NMS, etc. and outputs results in floating point.
When converting to TFLite, I have run into an issue with the Relu_6 operation. It does not have a specified range, so you must include one via the --default_ranges_max/min flag. I’ve set mine to 0 and 6 respectively, but I’m wondering if this will cause issues with accuracy and if there is something else I should be doing instead. Thanks!
A range of 0 to 6 makes sense for Relu6 but it may incur some precision loss. Exactly how much will depend on model training, dataset, domain, location of the Relu6, etc. I suggest running the model end-to-end with a large scale dataset and compare the results to the floating point version of the model.
Ideally, that Relu6 should have min/max ranges attached to it. We strategically place fake_quant_with_min_max_vars ops in the model to keep track of these ranges. The code that does this is here. What you want to do is get the name of the Relu6 op that’s missing ranges and call InsertQuantOp on it similar to line 124 of quantize.py.
What would be the simplest solution without changing tensorflow.contrib itself? I guess the issue is that the nodes FeatureExtractor/spaghettinet_edgetpu_l/Relu6 are not matched by _FindLayersToQuantize.
Output: 2022-05-02 13:52:04.556555: F tensorflow/lite/toco/tooling_util.cc:1728] Array FeatureExtractor/spaghettinet_edgetpu_l/Relu6, which is an input to the Conv operator producing the output array FeatureExtractor/spaghettinet_edgetpu_l/spaghetti_net/c0n0_0/expansion/Relu6, is lacking min/max data, which is necessary for quantization. If accuracy matters, either target a non-quantized output format, or run quantized training with your model from a floating point checkpoint to change the input graph to contain min/max information. If you don't care about accuracy, you can pass --default_ranges_min= and --default_ranges_max= for easy experimentation.
Thanks, I tried this before and it worked. But that probably causes a loss in accuracy since it assumes that activations are equally distributed between 0 and 6 as @Marie_White mentioned.
I think that there is an underlying issue in the quantization that this layer (FeatureExtractor/spaghettinet_edgetpu_l/Relu6) is not matched and therefore no quantization node is added.
With my post before I wanted to show which layer exactly is not quantized. Probably one would have to adapt the spaghettinet code or the quantization code in tensorflow.contrib. Unfortunately I don’t have the time to investigate further at the moment.
Ahh yes, I thought you might have already understood the solution. I’ve trained a model and got it running with pretty good results. Of course, the results are probably a bit worse than what the real solution would offer.
SpaghettiNet has a unique structure that will have a standalone activation function in the branch merging part of the network. This needs to be specially handled.
I cannot unit test so it would be better if someone here can help confirm that this fixes it Thanks for discovering all the issues in the open sourced models and hopefully we can help fixing those.
After digging further, I found out that the behavior that we encountered seems to be intended:
In quantize.py (line 294) quantization is skipped if an activation function immediately follows an addition or multiplication. When skipping an op for this reason during quantization, tensorflow outputs this: INFO:tensorflow:Skipping quant after FeatureExtractor/spaghettinet_edgetpu_l/add_13
In our example, the activation, which is missing range information, (FeatureExtractor/spaghettinet_edgetpu_l/Relu6) immediately follows an addition.
I’m not quite sure why it is beneficial to skip quantization in these cases but I hope there is a good reason for doing so. If anyone (like @Marie_White) can explain that, I’d appreciate it.
Your patch adds the missing quantization nodes but also adds quite some additional quantization nodes to the training graph (only the training graph, not the evaluation graph), which I think are not required (see my comment on your patch).
I changed the code to only include the required quantization nodes but I’m not 100% sure how generalizable my fix is.
Hi @Marie_White and @Isaac_Padberg. Thanks for the guideline you wrote. Have you been able to do a transfer learning on the SpaghettiNet? I am trying to do a transfer learning on the model based on my own data but the model format is in “tflite” and not “h5”, which makes me unable to access the weights and layers. Any solutions or suggestions for this?

 Thanks for discovering all the issues in the open sourced models and hopefully we can help fixing those.
Thanks for discovering all the issues in the open sourced models and hopefully we can help fixing those.