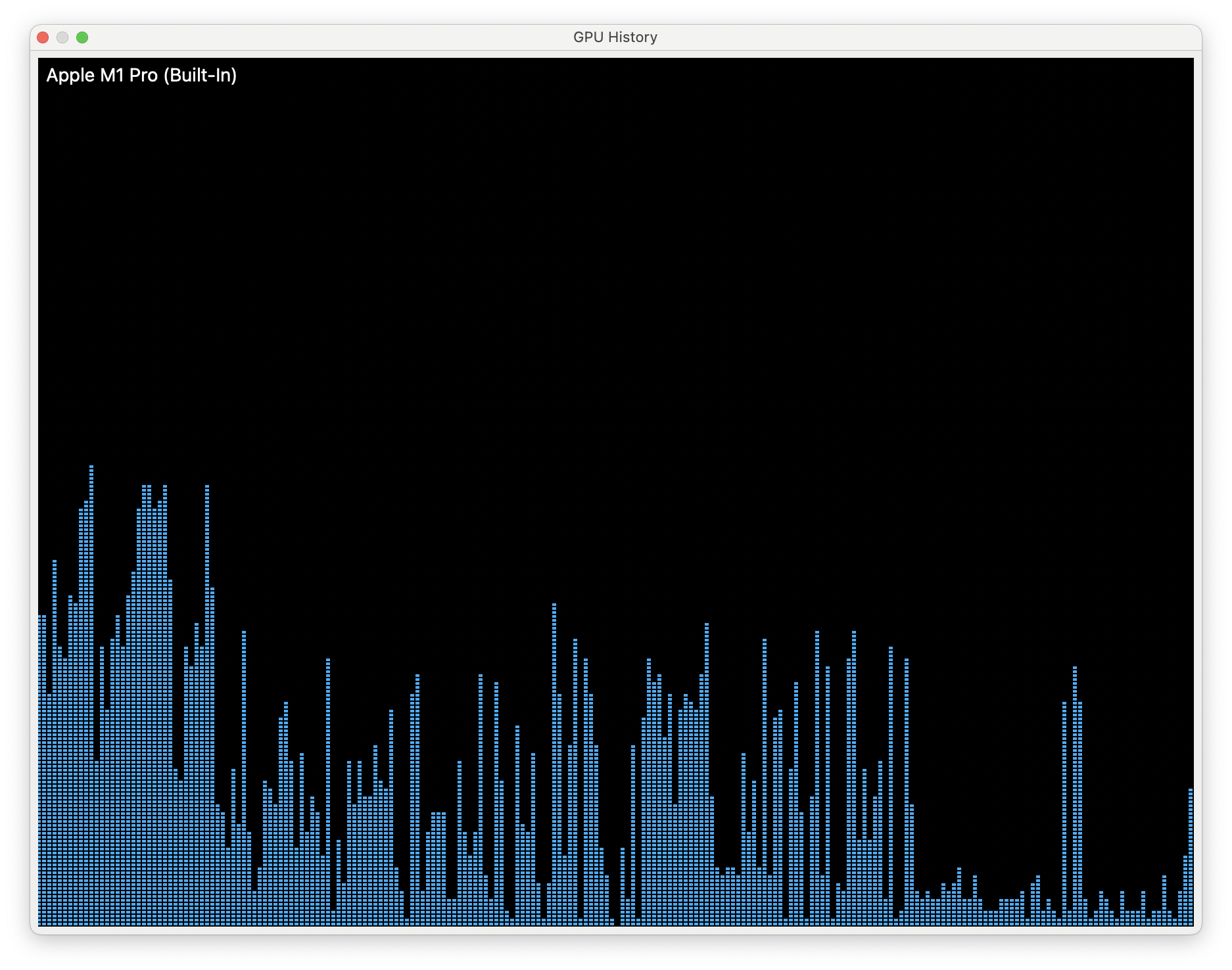
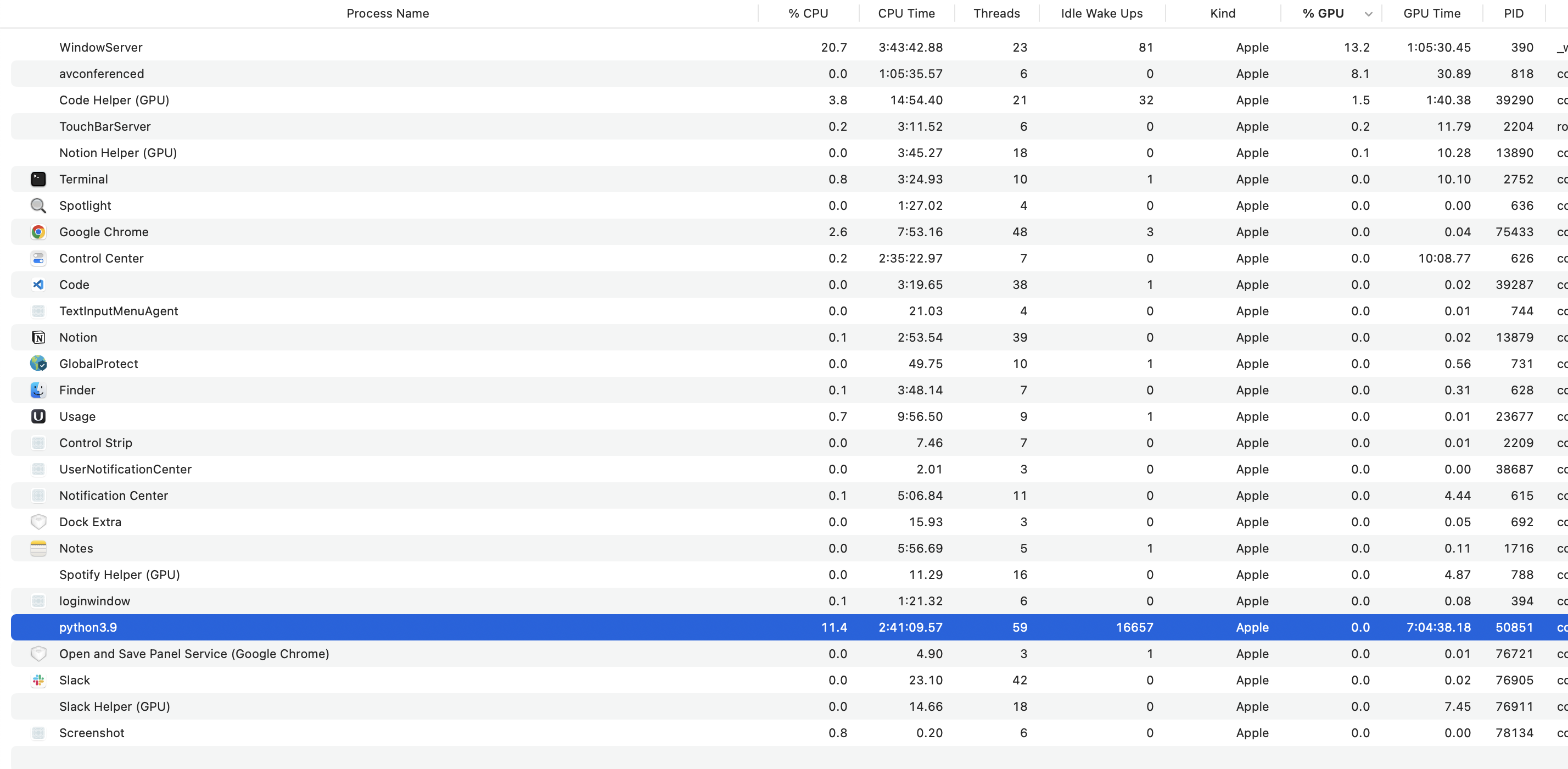
I’ve been utilizing TensorFlow with Python 3.9 to train a CNN model, and this process is enhanced by the Apple M1 GPU.
After 80 epochs, the process entered a sleep state (status S), and its GPU utilization dropped to 0 percent. I’m curious whether this training process caused the GPU to crash or if the operating system enforced the process to sleep due to excessive GPU usage/time
Please provide us some more details which TensorFlow version and metal version you are using in your macOS. Also if you could code share reproducible code to replicate and to understand the issue.
The possible cause can be when training process may no longer requires the full resources of the GPU or may be GPU overheats or becomes overloaded which made GPU to enter a sleep state in order to protect itself from damage.
You can also try training the model with a lower learning rate or a smaller batch size to reduce the GPU usage for preventing the GPU from entering into a sleep state.
Let us know if the issue still persists. Thank you.