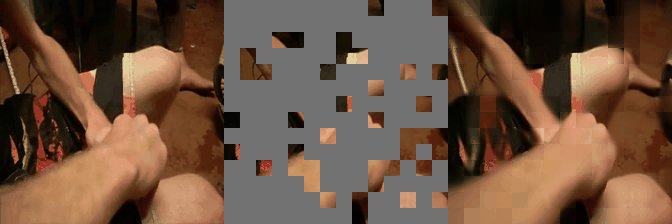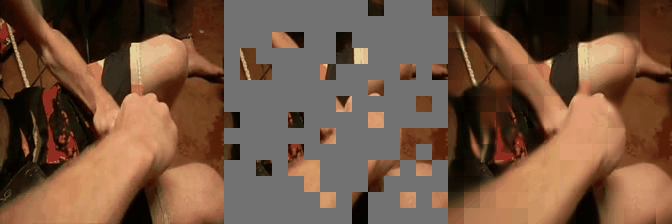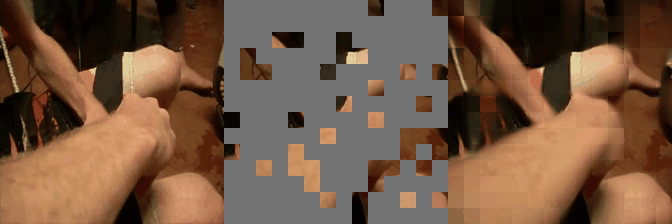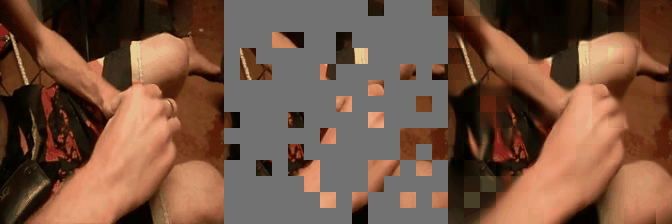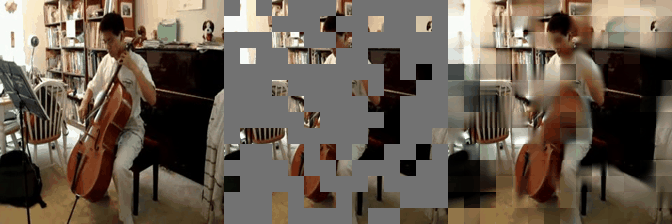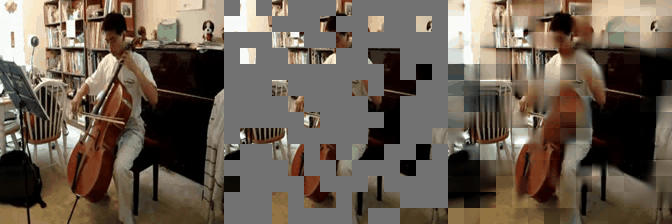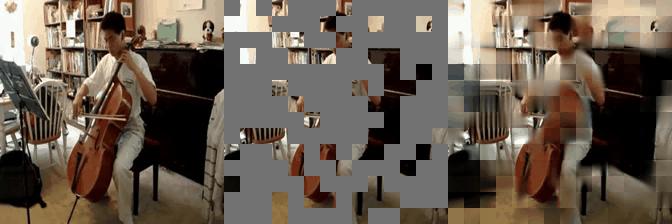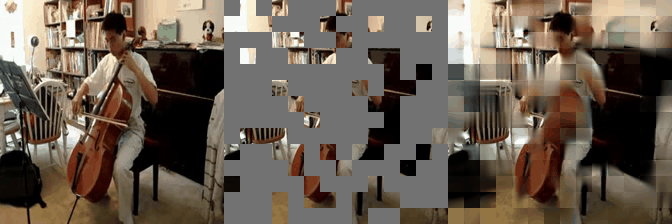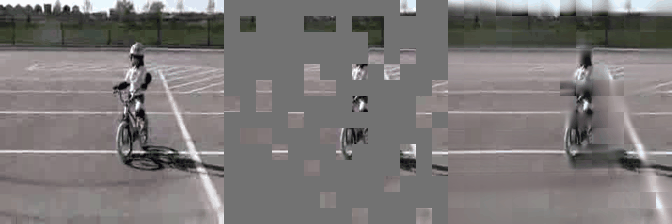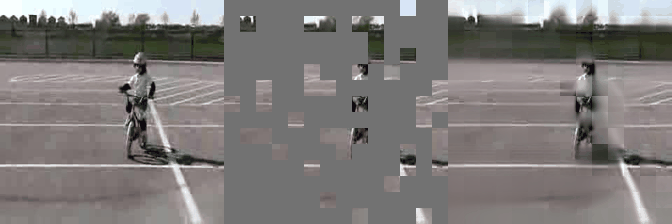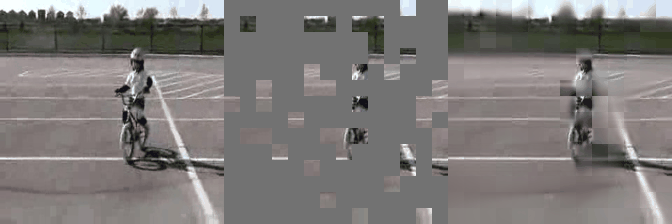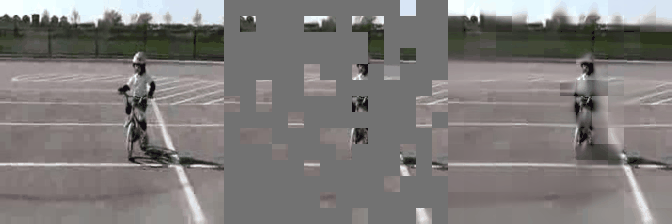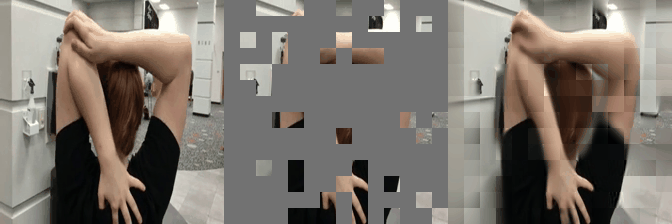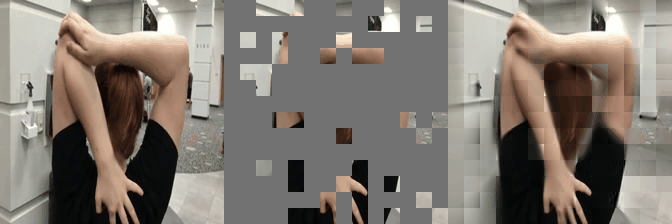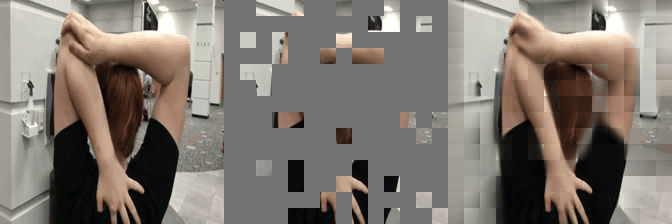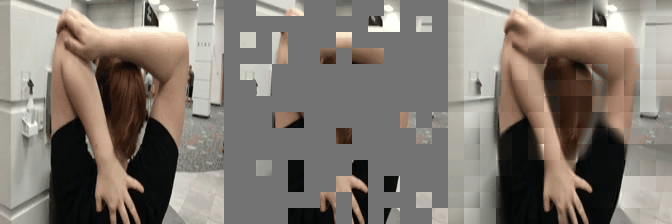We have implemented VideoMAE in #keras and ported the official #pytorch weights. Video masked autoencoder (VideoMAE) is a data-efficient learners for self-supervised video pre-training task, makes video reconstruction a more challenging self-supervision and encourages extracting more effective video representations.
Total 12 checkpoints are available in both #SavedModel and #h5 formats for top benchmark datasets, i.e. Kinetics-400, Something-Something-v2, and UCF101.
Inference
With the encoder model of VideoMAE, we can take inference on a video. For example, show below, a sample from Kinetics-400 test set.
from videomae import VideoMAE_ViTS16FT
>>> model = VideoMAE_ViTS16FT(
img_size=224, patch_size=16, num_classes=400
)
>>> container = read_video('sample.mp4')
>>> frames = frame_sampling(container, num_frames=16)
>>> y = model(frames)
>>> y.shape
TensorShape([1, 400])
>>> probabilities = tf.nn.softmax(y_pred_tf)
>>> probabilities = probabilities.numpy().squeeze(0)
>>> confidences = {
label_map_inv[i]: float(probabilities[i]) \
for i in np.argsort(probabilities)[::-1]
}
>>> confidences
{
'playing_cello': 0.6552159786224365,
'snowkiting': 0.0018940207082778215,
'deadlifting': 0.0018381892004981637,
'playing_guitar': 0.001778001431375742,
'playing_recorder': 0.0017528659664094448,
}

Visualization
Some reconstructed video sample using VideoMAE maksed autoencoder pretrained models with different mask ratio.